[인공지능] AI - CS231n 5강 Convolutional Neural Networks
cs231n 5강 youtube 강의 링크
cs231n 공개 강의자료
cs231n 과제 링크
CS231n 5강 - Convolutional Neural Networks
Keywords
- Convolutional Neural Networks
- Filter / stride / zero padding
- Activation map
- Pooling layer
- Max Pooling
드디어 강의 제목인 CNN에 도달했다. CNN은 간단하게 말하면 input 이미지의 일부들을 conolution하여 image map을 만들고 subsampling 한 뒤에 FC layer를 통해 출력을 만들어내는 것이다.
지난 시간엔 신경망을 살펴봤는데 본격적으로 들어가기 앞서 CNN의 역사에 대해 살짝 훑고 가자.
1. CNN까지의 역사
- MARK 1 Perceptron(1957): 단층 퍼셉트론으로 w값을 조절해서 학습했으며 w값을 업데이트하는 update rule이 처음 등장했다.
- Adaline/Madaline(1960): 최초의 Multi-layer Perceptron Network
이후, 처음으로 Backpropagation을 사용하는 모델이 나타났다. 하지만 Backpropagation을 바로 적용하려면 아주 세심하게 W를 초기화해야 했다. 2006년에 RBM을 이용해서 각 W를 학습시켰고, 이러한 hidden layer들을 이용해서 전체 신경망을 backprop.하는 식으로 fine tuning을 했다. 그러다 2012년에 CNN 기반의 alexNet이 세상에 나오게 되었다. 이때부터 급격하게 발전하기 시작한다.
구체적으로 CNN이 어떻게 유명해졌을까?
1950년대에 Hubel과 Wiesel이 이젠 익숙한 이름이죠?ㅎㅎ 단일 뉴런의 Receptive field에 대해 연구하였고 고양이를 대상으로 실험한 결과 뉴런이 oriented edges와 shapes에 반응한다는 것을 알아냈다. 또한 피질 내부에 topographical mapping(피질에서 가까운 세포는 시야에서도 서로 가까운 영역을 말함)이 있다는 점과 뉴런들이 계층 구조를 지닌다는 것도 발견했다.
너무 뇌과학쪽으로 가는 것 같아서 대충 요약하자면, corner나 bloc 등에 대한 아이디어를 얻게되었고 이를 통해 NN을 설계하여 backprop.과 gradient-based learning 등으로 문서인식, 우편번호의 숫자 인식에도 사용하게 되었다는 것이다.
나아가서, 나중에 배우게 될 detection이나 segmentation, pose recognition 등 CNN으로 아주 많은 것들을 할 수 있게 되었다.
cf) Style Transfer, Deep Dream
2. Convolutional Neural Networks

이전 시간에 우리가 배운 Fully connected layer는 그냥 image 자체를 쭉 늘려서 사용했었다. 위 예시처럼 image가 32 * 32 * 3의 정보를 갖는다면 32x32x3은 3072다 3072 * 1로 사용하여 가중치 W(10*3072)와 내적하여 1 * 10의 activation layer(map)을 얻었다.
Convolutional layer는 FC layer와 어떤 차이가 있을까? 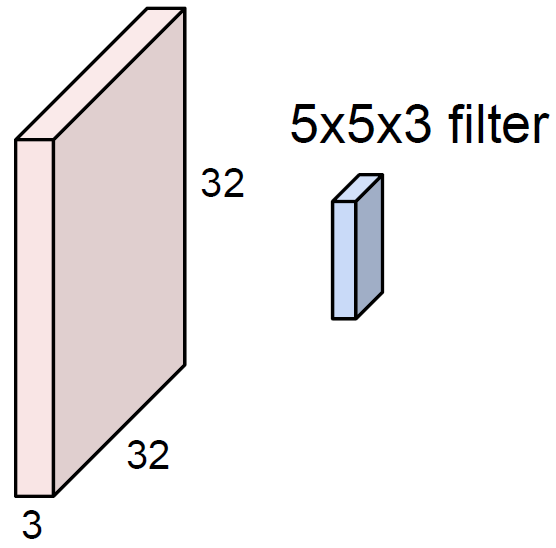
Convolutional layer는 이미지의 공간 정보를 보존한다. 공간 정보를 보존하려면 어떻게 해야할까? 우선, 공간 정보를 보존한다는 것은 activation map을 만들 때 일렬로 늘려서 사용하지 않는다는 말이다. 또한, 공간 정보를 보존하기 위해서는 filter를 사용해야 한다.
Filter는 항상 image와 depth가 일치해야 한다. 그래야 공간 정보를 다 보존할 수 있기 때문이다. 이제 해야할 일은 말 그대로 filter와 image를 convolve해야 한다. 신호 쪽에서 배운 합성곱은 하나의 함수와 또 다른 함수를 반전 이동한 값을 곱한 후, 구간에 대해 적분하여 새로운 함수를 구하는 연산자인데, 여기서는 엇비슷하다. 정확히 대응되진 않는 것 같다.
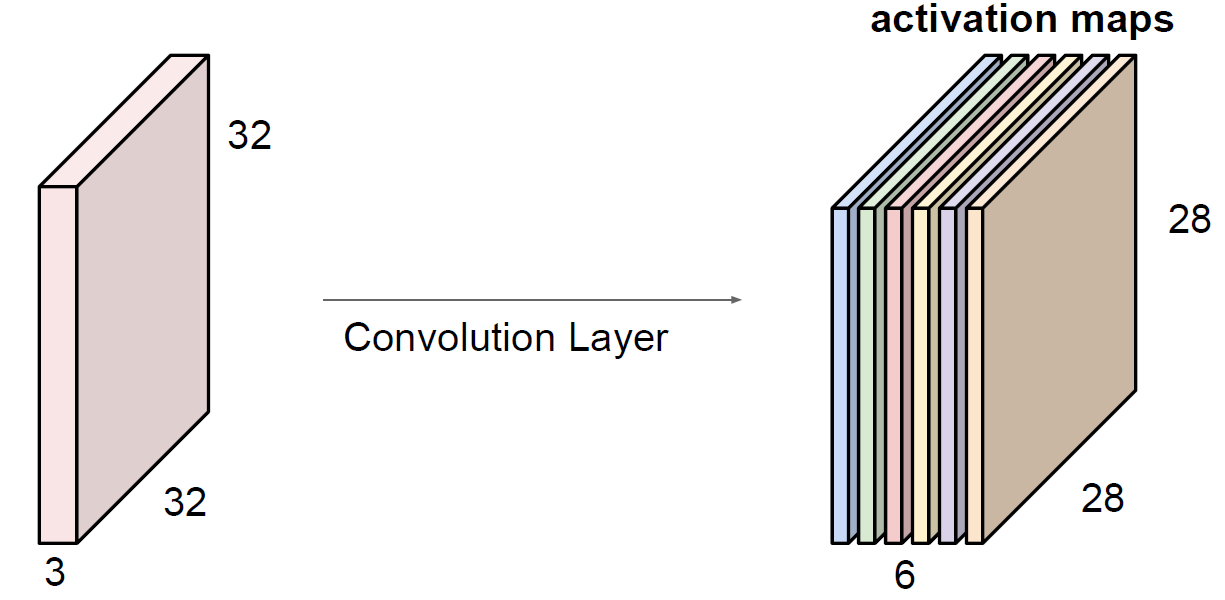
어찌됐든, 필터를 쭉 slide하면서 내적을 해주면 된다. 위의 예시에서 필터가 5X5X3이고 이를 w라고 한다면 wTx+b이다. b는 bias이고 결과는 28X28X1의 activation map이 나올 것이다. activation map의 개수는 결국 필터의 개수와 일치한다. 그렇기 때문에 예시에선 결과적으로 28X28X6을 얻게 된다. 필터의 개수가 6개이기 때문!!
Filter를 슬라이딩해서 얻은 결과인 activation map의 크기는 어떻게 결정될까? Filter의 크기도 중요하지만 Filter의 간격인 stride도 중요하다. Stride에 따른 activation map을 이해하기 위해 예시를 살펴보자.
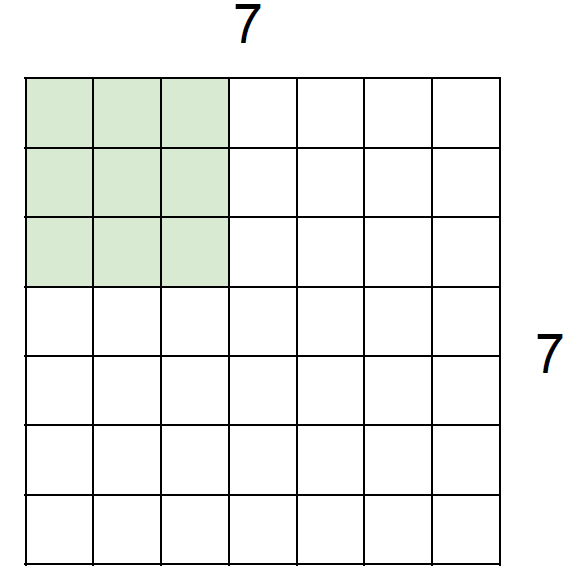
Q1. 7X7 입력에서 3X3 필터를 사용한다고 해보자. 결과물은?
5X5가 출력될 것이다.
Q2. 1번과 같은 조건에서 stride가 2라면?
3X3이 출력될 것이다. 말그대로 간격이 2이기 때문이다. 만약 이해가 가질 않는다면 기본 슬라이딩의 stride값이 1이라는 것을 생각하자.
Q3. 1번과 같은 조건에서 이젠 stride가 3이라면?
filter가 input에 fit하지 않기 때문에 적용 불가능하다. 적용하게하려면 다른 방식을 사용해야 한다.(zero-padding 등)
위를 토대로 공식화해보면 Output의 사이즈는 (N-F)/stride + 1임을 알 수 있다. N은 input image의 길이이며, F는 필터의 길이이다. stride가 3일 때 적용 불가한 것도 위 공식에 대입해서 계산해보면 수가 딱 떨어지지 않음을 알 수 있다.
이렇게 딱 떨어지지 않을 때 사용하는 일반적인 방법은 입력 이미지에 zero-padding을 하는 것이다. 이미지 모서리를 전부 0으로 감싸주는 것이다.
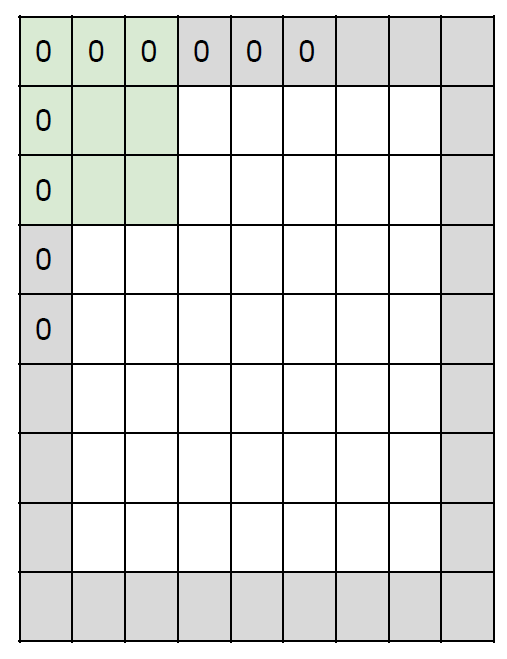
위와 같이 말이다. Zero-padding은 이뿐만 아니라 아주 놀라운 기능을 하나 더 가지고 있다. 바로 출력 이미지의 크기를 유지할 수 있단 점이다. 이전의 activation map은 전부 크기가 줄어들고 모서리의 정보가 누락되어왔기 때문에 이런 점은 매우 좋은 장점이다. zero-padding 덕에 마지막까지 이미지의 모든 부분을 전달할 수 있게 된 것이다.
Q1. 32x32x3이 주어지는데 2만큼 padding하고 stride 1을 쓰는 10개의 5x5 필터를 사용하면 output의 사이즈는?
(32+2*2-5)/1 + 1 = 32이다. 10개의 필터를 사용하므로 32x32x10이다.
Q2. 1번의 조건에서 해당 layer의 파라미터의 수는?
각 필터가 553+1개의 파라미터를 갖고 총 10개의 필터를 사용하기때문에 76*10, 즉 760개이다. 각 필터가 사이즈 이외의 파라미터가 더해지는 것은 bias에 관한 파라미터이다.
정보를 줄이고 싶지 않아서 zero-padding을 쓴다고 했는데 정보를 줄이고 싶다면 무엇을 쓸까? zero-padding을 쓰지 않고 stride, filter size를 적절히 조절해서 Conv layer에 통과시키는 방법도 있겠지만 일반적으로 pooling에서 이뤄진다.
Pooling layer는 downsampling을 하는 하나의 방법으로 여러 pooling 방식이 있지만 여기선 max pooling에 대해서만 소개한다.
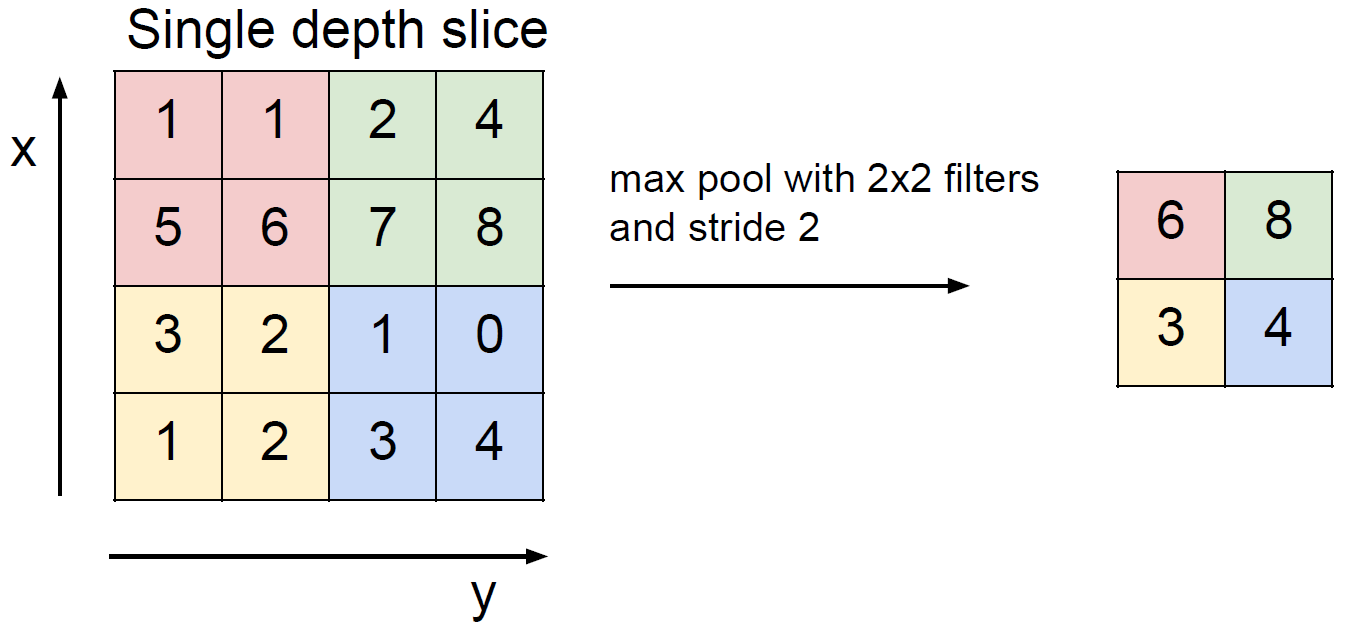
Max pool할 때, 주어진 조건(filter의 사이즈, stride 등)에 맞추어 나눠진 구역 중 제일 큰 값만을 취하는 것이다. 이렇게 하는 이유는 원래 이미지의 크기를 줄여야하는데 제일 신호가 센 것만을 살려두는 것이다.
또는 1x1의 convolution layer를 사용하는 방법도 있다. 
위와 같이 적용하는 1x1 필터의 개수에 따라 차원이 조절되는 것을 확인할 수 있다.
이렇게 Convolution layer에서 사용하는 다양한 기술들을 배웠는데, 그래서 실제로 이 layer에서 어떤 일이 일어나고 있는걸까? 이를 VGG의 예시로 시각화한 결과는 아래와 같다.
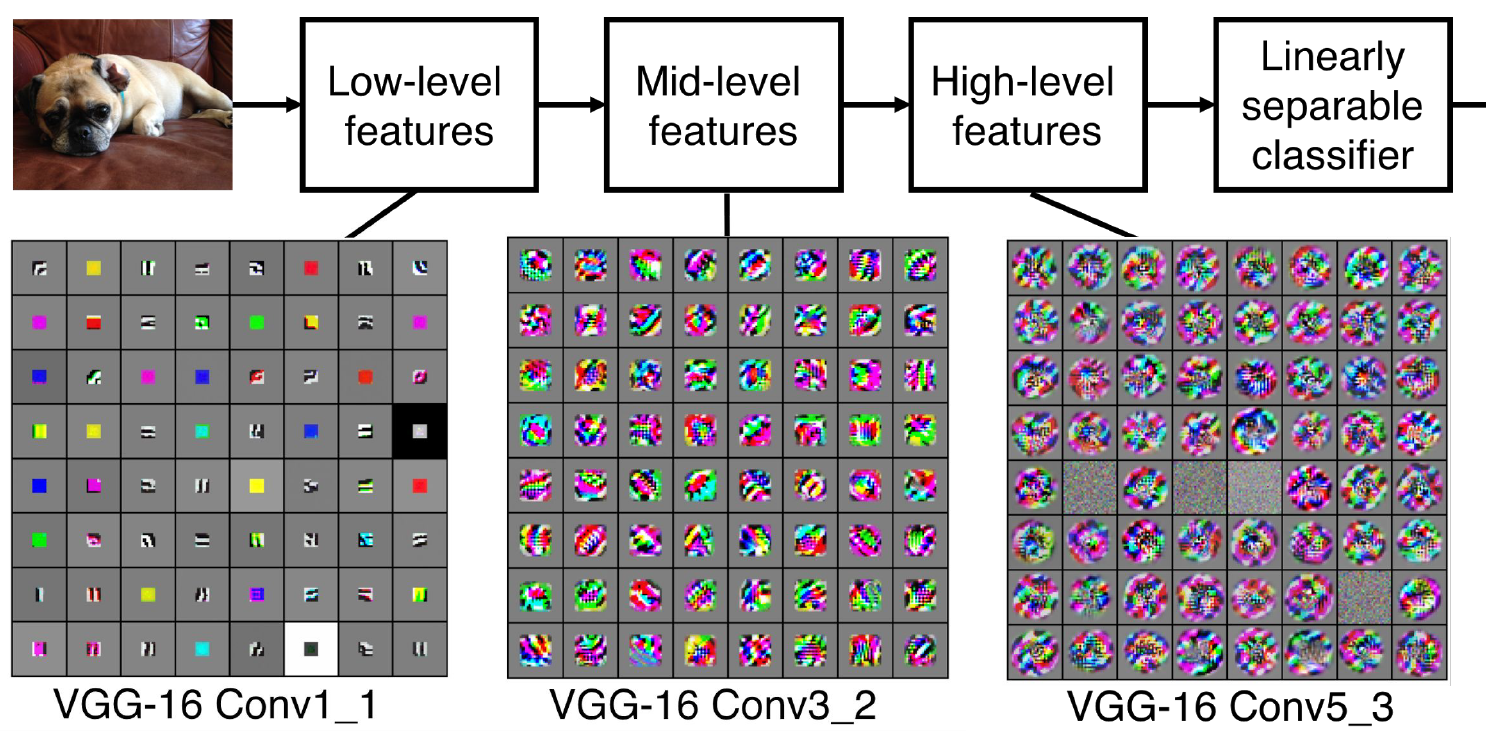
위의 그림은 image를 넣고 얻은 feature들을 시각화한 것인데 인간 관점에서 대체로 해석이 되는 것은 별로 없다. 그래도 알 수 있는 것은 Conv1_1에서는 low-level feature인 edges나 color를 학습하고 그 후에는 corner, blobs 등 높은 레벨의 특징을 학습하게 된다. 나중에 Visualization에 대한 여러 시도를 배우니 그때 좀 더 다뤄보자.

이렇게 우리는 ConvNet의 구조에 대해 어느정도 배웠다. 위 그림은 일반적인 ConvNet의 구조로 input image가 Conv layer와 ReLU 활성화 함수를 번갈아 통과하고 Pooling layer를 통과하는 묶음을 여러 번 반복하다 FC layer를 통해 답을 출력하는 것을 볼 수 있다.
이전 강의에서도 우리가 Neural Network가 우리의 뇌와 많이 닮아있다고 했는데 이런 뇌/뉴런 관점에서 Convolution layer를 살펴보자.
3. The brain/neuron view of CONV layers

위와 같이 뉴런의 관점에서 보면 Convolutional layer는 하나의 뉴런과 같다. 결과적으로 32x32x3에서 뽑아낸 28x28은 뉴런의 출력이고 각각은 입력 이미지의 조그마한 부분과 연결되며 모든 부분은 동일한 파라미터를 공유한다. 특정 부분만 처리하는 뉴런 여러 개가 모여 전체 이미지를 보게 되는 것과 유사하다.
이러한 비유를 FC layer에도 해보면 각 뉴런이 전체 입력 이미지를 한 번에 보는 것이라고 할 수 있다.
정리하면, Conv layer는 입력 이미지를 여러 작은 부분으로 나누어 바라보고 FC layer는 전체적으로 한 번 보는 것과 같다.
결론적으로 Convolution layer는 입력 이미지 일부분에서 특징을 추출하므로 전체 이미지에서는 여러 개의 특징을 추출할 수 있게 되어 이미지를 변형(확대, 축소, 이동)해도 이미지의 특징을 잘 찾을 수 있다. 그러나 FC layer는 이미지 전체에서 특징 하나(템플릿)를 추출하므로 효과적이지 않다.
