[인공지능] AI - CS231n 8강 Deep Learning Software
cs231n 8강 youtube 강의 링크
cs231n 공개 강의자료
cs231n 과제 링크
CS231n 8강 - Deep Learning Software
Keywords
- CUDA
- pre-fetching
- Deep Learning Frameworks
- Caffe, Caffe2 / Torch, PyTorch / Theano, TensorFlow / Paddle / CNTK / MXNet
- Static(Serialization) vs Dynamic Graphs(Conditional & loops)
1. CPU vs GPU
학부 때 우리가 코딩을 하게 되면 일반적으로 CPU만으로 연산을 처리하게 되서 GPU는 그저 게임을 하기 위해 필요한 것으로 생각하는 경우가 많다.요즘 글카가 너무 비싸요..
GPU는 Graphics Processing Unit의 준말로 강의날짜였던 2017년에서 현재인 2022년까지도 NVIDIA가 시장의 선두주자이자 독점적이다.
딥러닝의 경우 GPU를 필수적으로 사용하게 되는데 왜 그럴까? CPU와 GPU의 차이를 살펴보자.
CPU는 적은 코어 수를 갖으며 각 코어가 훨씬 빠르고 독립적으로 많은 일을 수행할 수 있다. 이것과 달리 GPU는 코어수가 많지만 독립적으로 많은 일을 할 수 없으며, 하나의 task를 병렬적으로 수행할 수 있다. 하나의 일을 병렬적으로 나누어 수행하는 특성으로 인해 딥러닝에서 쓰이게 된 것이다.
또한, 메모리 또한 차이가 있다. CPU에도 캐시 메모리가 있지만 대부분 메모리를 RAM에서 끌어다 쓰는데 GPU는 RAM이 내장되어 있다. 둘 다 캐싱 계층구조는 비슷
이런 점들이 어떤 차이를 낼까?
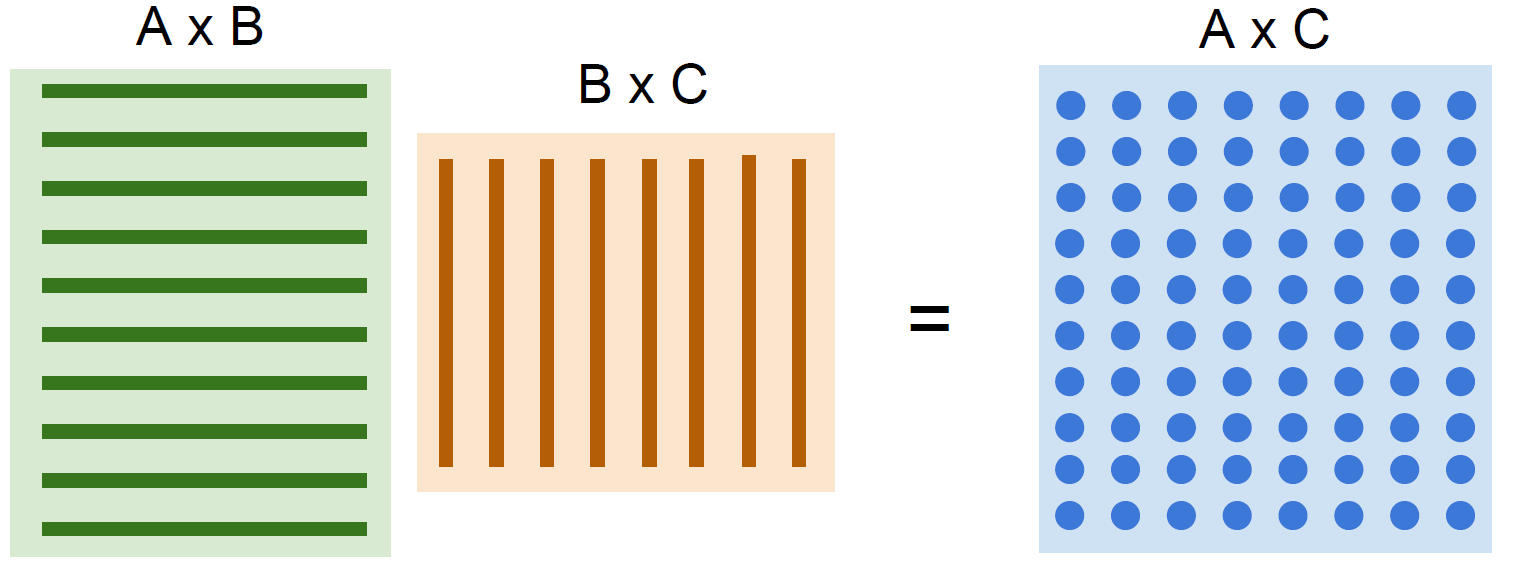
GPU가 CPU에 비해 월등하게 잘하는 연산이 바로 이러한 행렬 곱이다. Output 행렬의 값들은 input 행렬의 각 row와 column을 내적한 결과인데, 이는 모두 병렬적으로 연산 가능하다. 연산 값을 저장하고 다음 연산에 쓰이는 등의 연산이 없기 때문 이러한 연산을 GPU의 각 코어에 분배해서 빠르게 연산하는 것이다. 우리가 딥러닝에서 얼마나 많은 행렬 연산을 하는지 앞선 강의들에서 배웠기 때문에 왜 GPU의 처리량이 절실한 지 알 수 있을 것이다.
자 그럼, 이러한 GPU에서 실행되는 코드를 직접 작성할 수 있을텐데, 실제로 많은 사람들이 이렇게 할까? 우선 GPU에서 실행되는 코드는 c언어처럼 생긴 CUDA라고 한다.NVIDIA가 지원 이러한 CUDA code를 작성하는 것은 매우 어려운 일이기 때문에GPU의 성능을 극한으로 사용하기 어려움 ex)메모리 구조 관리 그냥 라이브러리를 사용하는 것을 추천한다. 가령, cuBLAS, cuDNN 등이 있는데, 행렬곱, convolution, forward/backword pass 등과 같은 기본적인 연산을 지원한다.
GPU가 그러면 최적화되어있는 도구냐? 그렇지 않다. GPU로 학습을 할 때도 문제가 있다. Model과 W는 GPU램에 있지만 실제 train data는 보조 기억장치에 있기 때문에 처리에 시간 차이가 있어서 bottleneck이 발생한다. GPU는 forward와 backword pass는 빠르겠지만, 디스크에서 읽어들이는 시간이 너무 오래 걸리는 것이다. 해결책으로는, 데이터셋 전체를 RAM에 올려 놓는 다던가(PC or Server), 보조 기억 장치로 조금 더 빠른 ssd를 사용하는 것이 있다. 또는 CPU의 멀티스레드를 이용해서 데이터를 RAM에 미리 올려 놓는 pre-fetching이 있다.
하지만 위와 같은 것들은 딥러닝 프레임워크를 사용한다면 이미 다 구현되어 있기 때문에 굳이 신경을 쓰지 않아도 된다. 알고만 있으면 좋을듯!!
2. Deep Learning Frameworks
딥러닝 프레임워크를 사용해야하는 이유는 다음과 같다.
- 쉽게 Computational graph를 build한다. (직접 만들지 않아도 된다)
- Computational graph에서 gradient를 자동으로 계산한다.
- GPU를 효율적으로 사용한다.
이하의 프레임워크들은 직접 사용해보고 정리글을 남기겠습니다
