[데이터 사이언스] Introduction
in CS Review on DataScience
Chapter 1: Introduction
- Motivation: Why data mining?
- What is data mining?
- Data Mining: On what kind of data?
- Data mining functionality
- Classification of data mining systems
- Top-10 most popular data mining algorithms
- Major issues in data mining
- Summary
Why data mining?
왜 데이터 마이닝이 필요한가?
이제는 데이터가 1초마다 폭발적으로 증가하고 있다. 당장 youtube만 봐도 기가바이트 단위의 영상이 1초에 몇 개나 올라올 지 감도 잡히질 않는다.
결국 데이터의 수집이나 사용성이 중요해졌고 그에 따라 자동화된 데이터 수집 도구나, 데이터베이스 시스템, 웹 등 다양한 도구들이 생겼다. 이러한 데이터의 주요 출처는 비즈니스(웹, 이커머스, 구매-트랜잭션, 주식 등), 과학(원격 감지, 생체 정보학, 과학적 시뮬레이션 등), 사회와 사람들(뉴스, 카메라, 유튜브) 등이 있다.
We are drowning in data, but starving for knowledge!
매우 익숙한 말이다. 데이터에 빠져살지만 정작 중요한 지식은 얻지 못한다는 말이다. 그래서 데이터 마이닝을 하기 시작한 것이다.
Evolution of Sciences
- Empirical science(~1600): 실험 등을 통해 무언가를 찾아내는 경험과학
- Theoretical science(1600~1950s): 이론적 모델이 중요하며 이를 통해 우리의 이해를 일반화 함
- Computational science(1950s~1990s): 시뮬레이션을 통해 복잡한 수학적 모델을 풀 수 있게 되며 시간을 많이 절약할 수 있게 됨
- Data science(1990~현재): 엄청난 양의 데이터가 등장하면서 이를 잘 관리하고 저장하며 새로운 지식을 얻는 것이 중요해짐
Evolution of Database Technology
1960s : 데이터가 많이 없으니 ‘데이터 수집’, ‘데이터베이스 생성’, IMS and network DBMS
1970s : 관계형 데이터 모델, 관계형 DBMS 구현
1980s : 관계형 데이터 베이스에서 확장된 관계형 DBMS, 응용 중심 DBMS(공간 데이터베이스 등)
1990s : 데이터가 많이 쌓여서 데이터 마이닝의 필요성이 생겨나고 data warehousing, multimedia DB, Web DB 등장
2000s : 데이터 마이닝과 그의 응용
2010s : 빅데이터, 인공지능, 머신러닝
What is data mining?
그렇다면 데이터 마이닝은 무엇인가?
데이터 마이닝은 쉽게 말하면 데이터로 부터 지식이나 흥미로운 패턴을 발굴하는 것이다. "사소하지 않고(non-trivial), 숨겨져 있고(implicit), 이전에 알려지지 않은(previously unknown) 동시에 잠재적으로 유용한 것(potentailly useful)"을 흥미로운 것(interesting)으로 정의할 수 있겠다.
하지만 데이터 마이닝 용어 자체는 약간 이름을 잘못 지었다고도 할 수 있다. 예를 들어 gold mining은 광산에서 금을 캐는 것인데 데이터 마이닝을 여기에 빗대면 데이터에서 데이터를 캐는 이상한 말이 된다. 물론 그 데이터가 유용한 데이터이다라는 것이 생략되었겠지만 knowledge mining이라고 했으면 더 와닿지 않았을까?
그래서 이런 데이터 마이닝의 다른 이름으로는 knowledge discovery in databases(KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting, business intelligence 등이 있다. 적고 보니 뭐 이리 많은지..
참고로, 간단한 search나 query processing 혹은 deductive expert systems(explicit한 정보와 룰이 주어져있을 때 이를 통해 단순한 정보를 추출하는 과정) 같은 경우를 데이터 마이닝이라고 하지는 않는다.
아래는 KDD의 프로세스이다. 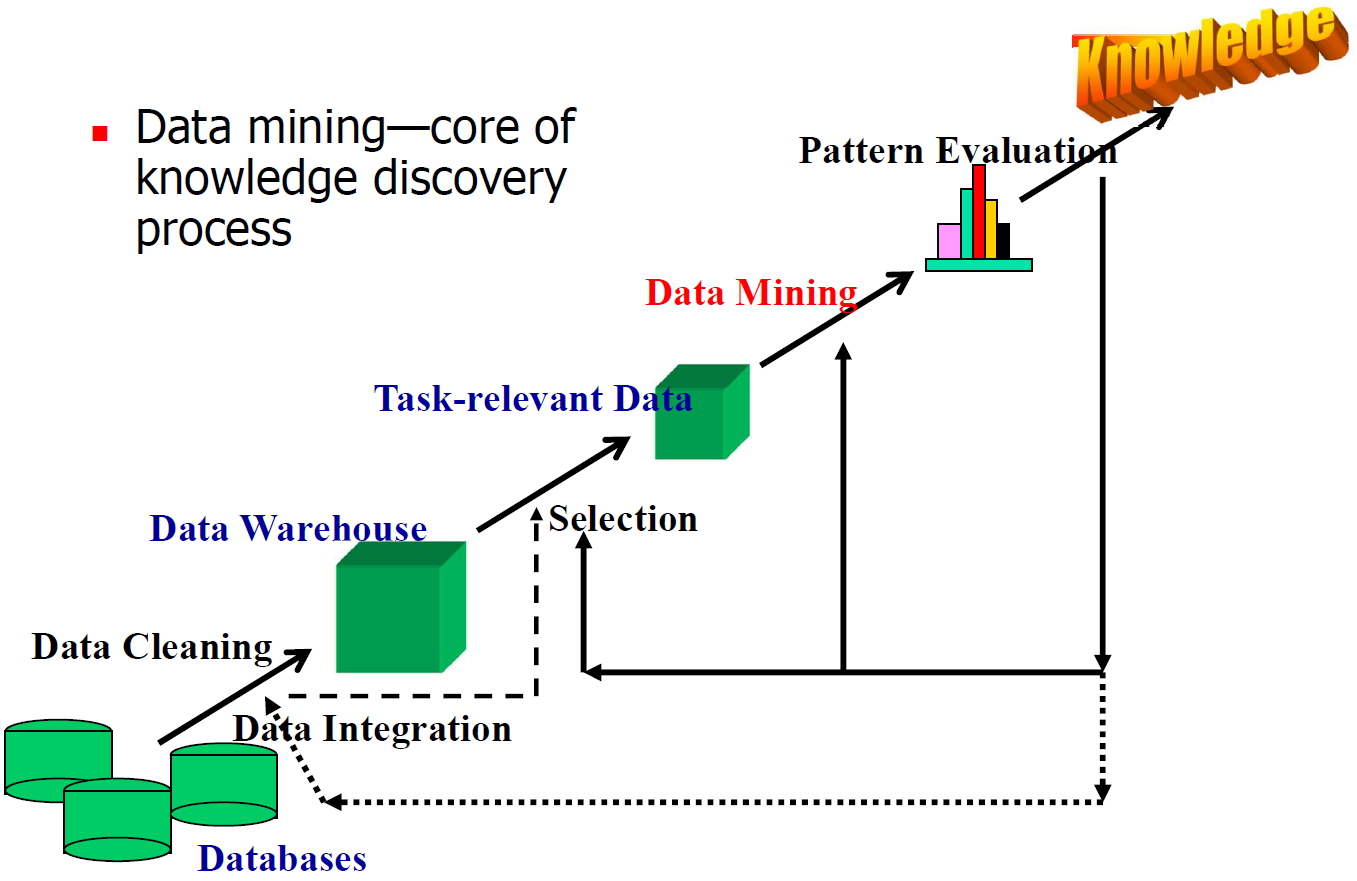
1) Data cleaning: 데이터 마이닝의 질을 높이기 위해 noise, missing data 문제를 해결
2) 여러 데이터베이스를 통합(Data integration)하고 이 때 발생하는 일관성과 같은 문제를 해결한다. 그 결과물이 data warehouse(DB의 DB, DB의 스냅샷, non-dynamic)이다.
3) Data warehouse에서 해당 작업과 관련된 데이터를 선택한다. 해당 작업을 풀기 위해 필요한 데이터만을 선택(data selection)한 것으로 이러한 데이터를 Task-relevant Data라고 한다.
4) 데이터 마이닝을 거쳐서 나온 것 중에서 pattern evaluation을 통해 knowledge를 추출한다.
아래는 business intelligence의 프로세스이다. 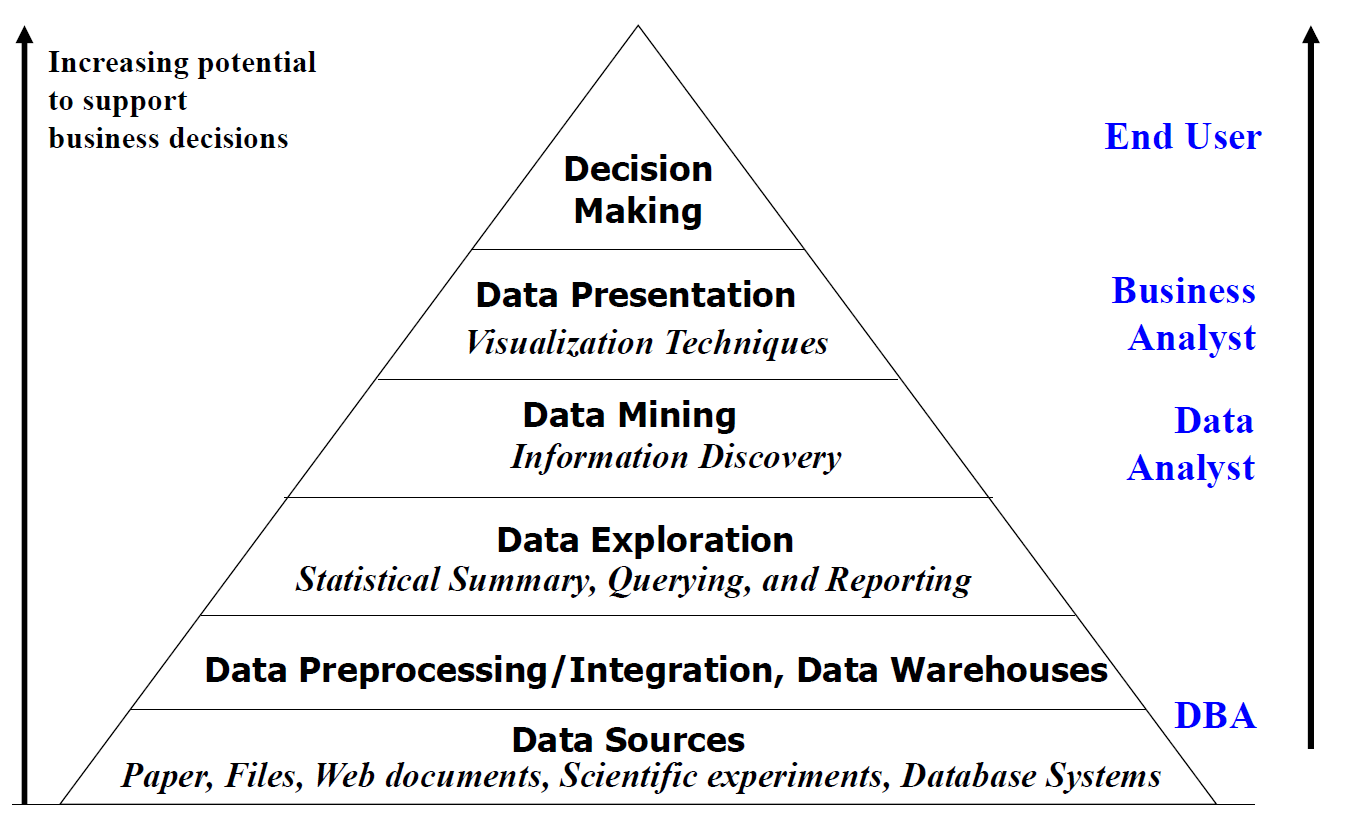
DBA(DB administrator)가 data sources를 관리하고 Data 전처리 및 통합, Data warehouse를 구축하기도 하며 Data exploration 또한 한다.
Data Analyst 또한 data exploration(통계적인 요약, 쿼리, 리포트)에 관여를 한다. Data analyst는 여기서 얻은 정보를 바탕으로 data mining을 통해 knowledge를 끄집어낸다.
위에서 얻은 knowledge를 Visualization하는 기술이 필요한데 이를 business analyst가 관여한다.
결과적으로 이를 보고 end user가 의사결정을 내리게 된다.
Data Mining: Confluence of Multiple Disciplines
데이터 마이닝은 여러 분야가 융합된 것이다. Database 기술, 통계학, 알고리즘, 패턴 인식, 머신 러닝 등 아주 다양한 분야가 관여한다.
전통적인 data analysis가 안되는 이유는?
- 어마무시한 양의 데이터
- 매우 높은 차원의 데이터
- 매우 복잡한 데이터
- 새롭고 정교한 어플리케이션
Data Mining: Classification Schemes
일반적인 분류로는 Descriptive data mining(현재의 데이터가 어떤 상태인지를 요약, 기술)과 predictive data mining(현재의 데이터로 새로운 데이터 예측)으로 나눌 수 있고, 관점이 다르면 분류 또한 달라진다.
Data mining의 분류 관점
- Data 관점: 마이닝할 데이터의 종류 ex) 관계형, 데이터 웨어하우스, 트랜잭션, 스트림, 객체 지향/ 관계형, 능동형, 공간형, 시계열, 텍스트, 멀티미디어, WWW
- knowledge 관점: 검색할 지식의 종류 ex) Characterization, 식별, 연관성, 분류, 클러스터링, 추세/경향, 특이치 분석 등
- Method 관점: 활용할 기법의 종류 ex) 데이터베이스 지향, 데이터 웨어하우스(OLAP), 머신 러닝, 통계, 시각화 등
- Application 관점: 적용된 어플리케이션의 종류 ex) 소매, 통신, 은행, 사기 분석, 바이오 데이터 마이닝, 주식 시장 분석, 텍스트 마이닝, 웹 마이닝 등
Data for mining
- DB-oriented 데이터셋과 어플리케이션(DB 기준)
- RDB, data warehouse, transactional DB
- 최신의 데이터셋
- Time-series data, Object-relation DB
- Spatial data
- Text DB 등
Functionalities for data mining
- Multidimensional concept description: characterization & discrimination ex) 건조한 지역 vs 습한 지역
- Frequent patterns, association, correlation vs causality ex) 기저귀 → 맥주[0.5% 75%] -> Association
- Classification and Prediction: 설명하고 구별하는 모델(함수)을 구성 ex) (기후)에 따라 국가 분류 또는 (연비 기준)에 따라 자동차 분류, 알 수 없거나 누락된 숫자 값 예측
- Cluster analysis: 클래스 레이블을 알 수 없기에 데이터를 그룹화하여 새 클래스를 만든다, 클래스 내 유사성 극대화 및 클래스 간 유사성 최소화
- Outlier analysis
Outlier: 전체적인 경향을 준수하지 않는 데이터 object, Noise인가 exception인가? 부정 행위 탐지, 희귀 사건 분석에 유용 - Trend and evolution analysis ex) 추세 및 진화 분석
Top-10 most popular data mining algorithms
- C4.5
- K-Means
- SVM
- Apriori
- EM
- PageRank
- AdaBoost
- KNN
- Naive Bayes
- CART
Major issues in data mining
- Mining methodology
- 다른 종류의 knowledge를 다양한 데이터 타입에서 마이닝 ex) bio, stream, web
- 성능 문제: Efficiency(얼마나 효율적인가, 일을 효율적으로 처리), Effectiveness(얼마나 효과적인가, 효과적인 무언가를 달성), scalability
- Pattern evaluation: 어떤 것이 interesting한가
- Background knowledge를 이용해서 도출
- Noise와 incomplete data 처리
- 병렬적, 분산 컴퓨팅, incremental mining(추가 데이터 결과와 기존 결과 합치기, 추가 데이터와의 통합)
- User interaction
- Data mining query languages
- Visualization
- 여러 level의 abstraction
- Applications and social impacts
- 특정 도메인과 데이터 보안 이슈
Summary
- Data mining: 대용량의 데이터로 부터 interesting한 패턴을 끄집어 내는 것
- KDD process: DB들로부터 data cleaning, data integration해서 data warehouse 만들고 data selection, transformation해서 task-relevant data 만들고 이에 대해 data mining하면 pattern이 나오고 여기에 interesting measure로 pattern evaluation해서 knowledge를 얻는다.
- 다양한 DB에 대해 마이닝을 할 수 있다.
- Characterization, discrimination, association, classification, clustering, outlier and trend analysis
- 데이터 마이닝 시스템과 아키텍처
- 데이터 마이닝의 주요 이슈
