[데이터 사이언스] Recommendation Systems: Concepts, Techniques, and Applications
in CS Review on DataScience
이번 강의는 Recommendation system의 관한 내용으로 김상욱 교수님 연구실 성과를 비롯해 여러 논문들을 짧게 살펴볼 예정이다.
Contents
- Recommendation Systems: An Overview
- Concepts and Applications
- Collaborative filtering (CF)
- Exploiting Uninteresting Items for Effective CF
- Ratings setting (ICDE16, WWW18, TKDE20)
- One-class setting (AAAI18)
- Recent Related Research
- GAN-based imputation and CF
- Learning multi-type pair-wise preferences for CF
- TV show Recommendation
- Adversarial Signed Network Embedding
- Community reinforcement on graphs for community detection
- Graph engine for high-performance graph processing
Recommendation Systems
Concepts and Applications
사용자의 평가, 구매 및 검색 기록 등을 활용해서 사용자가 원하는 몇 가지 아이템들을 보여준다.
사용자가 신발 여러 켤레를 구매했다면, 이를 바탕으로 사용자의 선호도를 분석하고 사용자가 원할 것 같은 몇 가지 항목을 선택해서 보여준다. 이렇게 Recommendation system이 동작한다.
아마존, 네이버 쇼핑, 넷플릭스, 왓챠 등 많은 application들이 이미 이 시스템을 사용하고 있다.
Recommendation system은 다음 4 가지의 approach로 분류할 수 있다.
- Content-based approach: 활성 사용자의 즐겨찾기 항목과 내용이 유사한 항목 추천
- Collaborative filtering(CF) approach: 활성 사용자와 유사한 이웃에 의해 높게 평가된 항목 추천
- Trust-based approach: 사용자 간의 신뢰 관계에 따라 항목 추천
- Hybrid approach: 위의 접근방식을 조합하여 아이템 추천
위 4 가지 중 우리는 CF approach에 집중할 것이다. 순서는 다음과 같다.
1단계: 활성 사용자 c와 유사한 사용자(이웃) 그룹 찾기
2단계: item s에대한 c의 rating을 rc,s이라고 하면 이를 예측해야 한다. 이 때, c의 이웃들이 해당 item s에 준 rating을 기반으로 예측한다.
3단계: Rating이 높은 순서대로 소수의 item을 추천한다.
결과적으로, 각 유저들과 아이템 사이의 rating matrix가 곧 input data이다. 아래 그림을 보자. 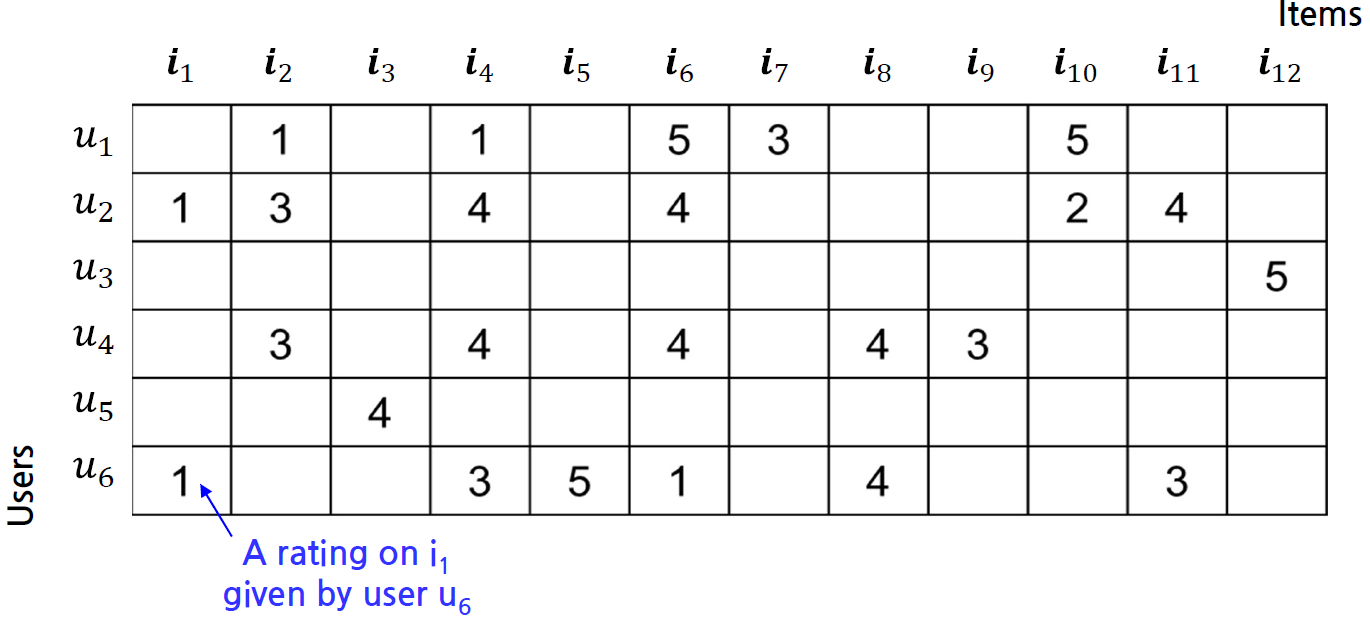
다시 1단계로 돌아가 이웃을 찾아야 하는데, 여러 가지 방법이 있다.
먼저 Heuristic-based method를 살펴보자.
유저 간 Similarity를 측정하는 measure로 Pearson correlation coefficient(PCC)가 있다. 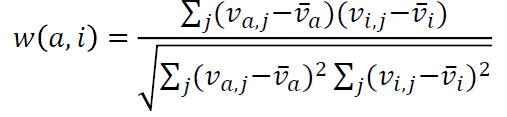 위의 식에서 a, i는 각각 유저를 말한다.
위의 식에서 a, i는 각각 유저를 말한다.
다른 measure로 Cosine similarity가 있다. 마찬가지로 유저 a와 i에 대해 similarity를 측정하는 도구이다. 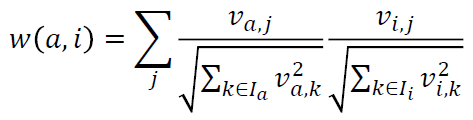
Machine-Learning based method도 있다.
제일 널리 쓰이는 Matrix/Tensor Factorization이 있고, social network Analysis, deep learning 등이 쓰인다. Matrix Factorization은 비어 있는 rating matrix를 두 개의 matrix로 인수분해하듯 분해하는데 이때 값을 잘 추정해서 만든다. 다시 두 개의 matrix를 곱하면 비어있던 부분들이 채워지고 이를 rating으로 사용하는 것이다.
2단계에서 rc,s을 찾아야 한다. 공식은 다음과 같다. 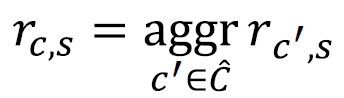 이 때, C hat은 유저 c의 이웃들의 집합이다.
이 때, C hat은 유저 c의 이웃들의 집합이다.
이외에도 다음과 같은 공식이 있다. 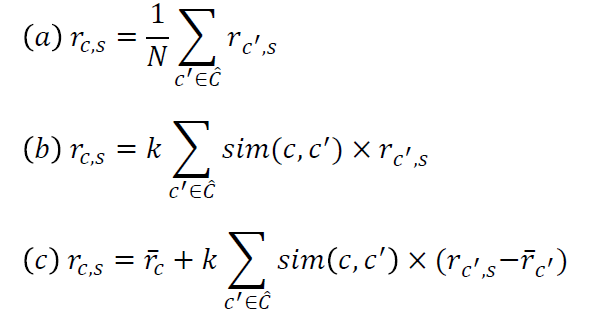
Exploiting Uninteresting Items for Effective CF
“Told You I Didn’t Like it”
CF 접근 방식은 사용자가 제공하는 rating에만 초점을 맞춘다. 이로 인해 data sparsity 문제(대부분의 사용자가 아주 일부만을 평가, 약 4%)가 있다. 그렇기 때문에 CF 접근 방식은 낮은 정확도와 좁은 적용 범위라는 한계가 있다.
Rating이 지정되지 않은 항목 즉, Uninteresting items를 이용하는 것이 아이디어의 핵심이다. Rating matrix에서 평가되지 않은 방대한 수의 항목을 활용하면 CF 접근 방식이 크게 개선될 것이라는 가설에서 출발한다.
Unrated item들은 크게 두 가지로 나누어 생각해볼 수 있다. 첫째로, 사용자가 아이템의 존재를 알지 못하는 상황이다. 이는 추천의 후보가 된다. 혹은 사용자가 알고는 있었지만 좋아하지 않았기 때문에 구입하지 않았고 따라서 rating이 매겨지지 않은 것이다. 후자의 경우를 Uninteresting items로 정의한다. 결과적으로, 사용자가 부정적인 선호도를 가진 item이다.
이제 preference를 두 가지로 구분해야한다. Pre-use preferences와 Post-use preferences이다. Pre-use preferences는 구매 및 사용 전 아이템에 대한 사용자의 인상으로 item의 meta data로 결정되어 구입 전에 알 수 있다. Post-use preferences는 아이템 구매 및 사용 후 사용자의 인상으로 item의 실제 내용을 통해 결정되어 구입하기 전엔 알 수 없다.
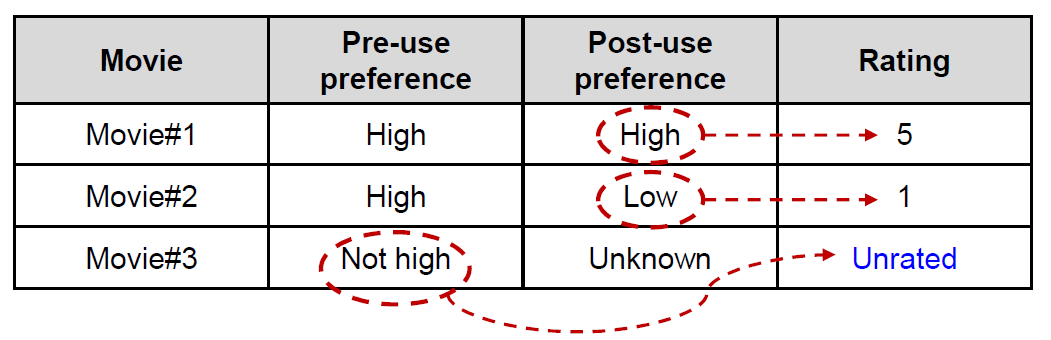
위의 표를 보면, 영화 1과 2는 pre-use preference는 높아 구매해서 봤는데 1번은 좋았으나 2번은 좋지 않았던 경우이다. 또 영화 3은 pre-use preference가 낮아서 구매하지 않았고 결과적으로 unrated인데, 이 때 3번은 결국 uninteresting item인 것이다. 1과 2는 interesting item이지만 전자는 선호했고 후자는 선호하지 않았다. 이를 벤다이어그램으로 나타내보면 아래와 같다.
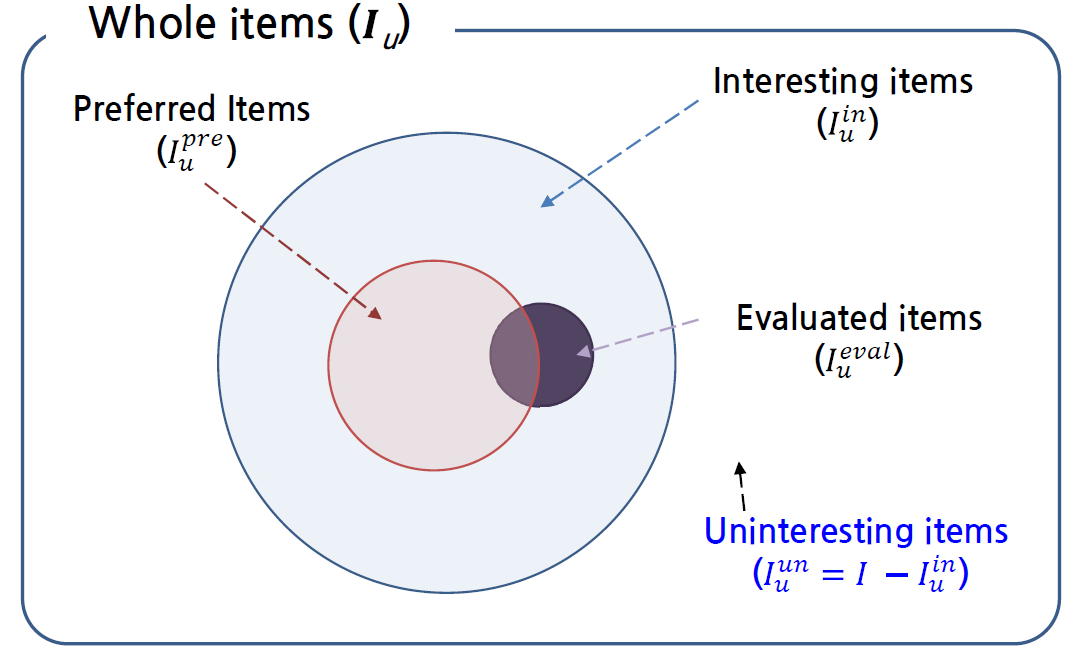
이제, uninteresting item이 유용한 것은 알았지만 이를 unrated item들 중에 어느 것이 uninteresting하는 지를 아는 것이 challenge이다. 위에서 보았듯, 사용자의 pre-use preference가 상대적으로 낮다는 것을 알게 되었다. 결과적으로, rated item들에 대해서는 pre-use preference에 제일 높은 점수를 부여하고(낮았다면 애초에 구매조차 하지 않았을 것이므로), unrated item들에 대해서는 rated item들에 대한 pre-use preference로 추론한다.
최종 목표는 상위 N개의 item을 추리는 것으로 모두 interesting item이면서 post-use preference도 높아야 한다. Uninteresting item들에 대한 전략으로 두 가지를 생각해볼 수 있다. 최종 추천 목록에서 uninteresting item을 제외하거나, CF에서 uninteresting item과 rated item을 모두 활용하는 것이다.
찾아낸 uninteresting item들에 대해서 0을 삽입하는 것을 zero-injection이라고 한다. 아래의 그림을 보자.
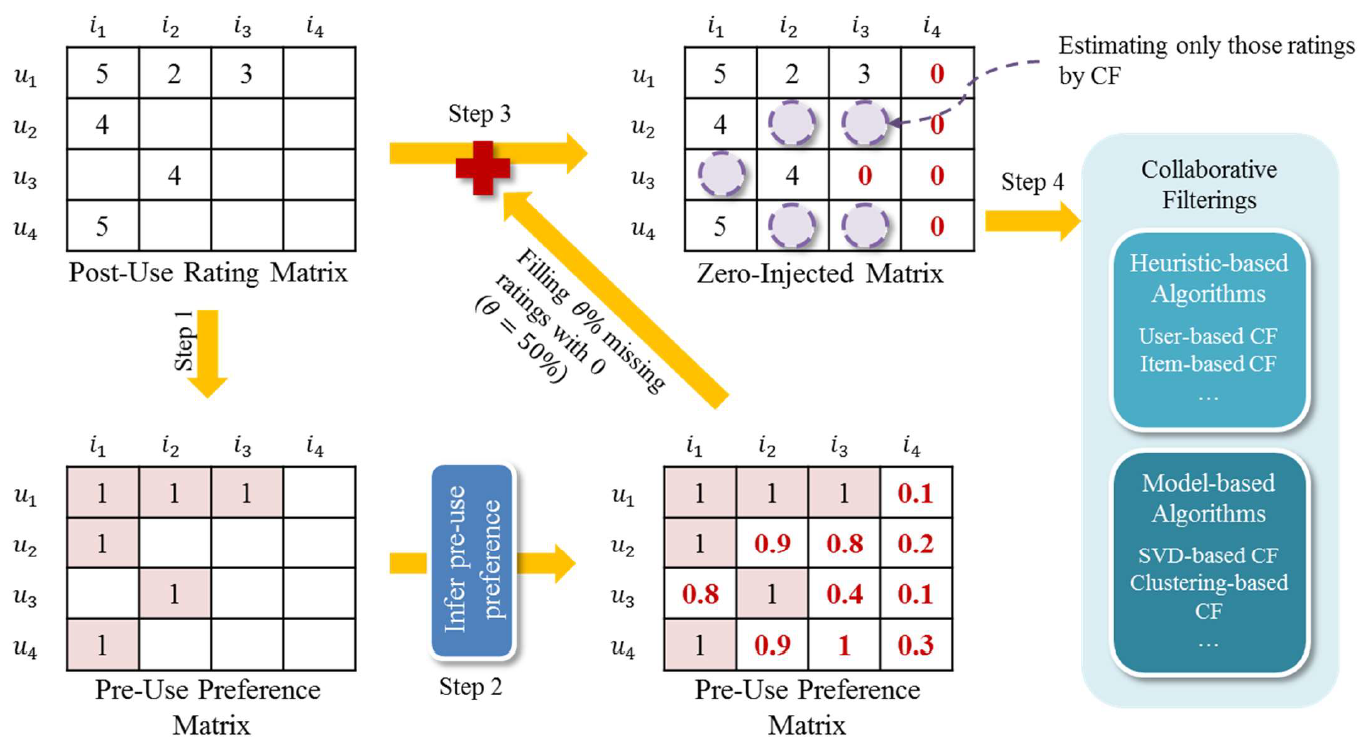
Post-use rating matrix에서 pre-use preference matrix를 만들고 pre-use preference를 추론한다. 이렇게 만들어진 matrix로 rating matrix의 uninteresting item들을 0으로 채워넣는 것이다. 이후 이 matrix를 Heuristic-based method, deep learning based 등의 방식으로 활용하는 것이다.
이 방법의 강점으론 CF method들을 향상시킬 수 있다. Recommendation list에서 uninteresting item들을 제외할 수 있고, 보다 dense한 rating matrix(zero-injected matrix)로 CF를 할 수 있게 된다. 이는 단순히 rating matrix를 zero injected matrix로 대체하면 되고, 기업은 적절히 CF method를 선택하면 되는 일이다. 즉, 기존의 CF method와 무관하다.
파라미터인 세타를 10과 90사이의 값으로 설정하면 대체로 좋은 결과를 얻을 수 있다.
How to impute missing ratings? Claims, Solution, and its application to CF
Data imputation이란 앞서 말한 data sparsity problem에 대한 해결책으로 기존 rating으로 결측치를 추론하는 것이다. 장점으로는 신뢰 네트워크 및 크라우드 소싱과 같은 다른 소스의 추가 정보가 필요하지 않다는 것이다.
- Group M
Missing rating을 Multiple value로 추론한다. 이미 있는 값과 CF를 통해 결측치를 결정한다. ex) AutAI, AdaM - Group S
Missing rating을 Single value로 추론한다. Missing rating은 유저의 부정적 선호도라고 생각하고 모두 0과 같은 낮은 값으로 채워넣는다. ex) PureSVD, Zero-injection, AllRank(모두 2)
위 논문의 주요 contribution은 기존의 data imputation 접근 방식의 한계를 지적하고 이를 극복하기 위해 3 가지 주장을 제안한다. 또한 딥러닝 기반의 data imputation approach를 제안하고(항목에 대한 선호도에 대한 가설을 기반으로, 3 가지 주장 만족), 실제 데이터 세트에 대한 광범위한 실험을 수행하는 방법(주장과 가설 검증을 위해)을 제시한다.
가정은 시간과 예산에 제약이 있는 사용자로 missing rating의 특성은 몇 가지의 흥미로운 항목과 방대한 수의 관심 없는 항목으로 이루어져 있다. 세 가지 claim을 살펴보자.
- Claim 1 : 대다수의 imputed value는 low rating일 것이다.
- Group M의 한계를 극복하기 위함이다.
- 대다수가 uninteresting item인데 group M은 다수의 결측치가 높은 값일 것으로 추론한다.
- MovieLens, CiaoDVD, Watcha의 데이터로 실험을 해보니 대다수의 imputed value가 3 이상이라는 것을 확인했다.
- 또한, imputed value가 낮은 rating인 경우에만 추천의 정확도가 높은 것을 확인할 수 있었다.
- Group M보다 Group S의 정확도가 더 높다.
- Claim 2 : Interesting item의 imputed value는 uninteresting item보다 높아야 한다.
- Group S의 첫 번째 한계를 극복하기 위함이다.(Zero-injection, PureSVD, AllRank)
- Group S는 소수의 interesting item을 무시한다.
- Interesting item에 더 높은 rating을 부여할 때 정확도가 높아지는 것을 확인했다.
- Claim 3 : Imputed value는 item에 부여할 수 있는 range에 속해야 한다.
- Group S의 두 번째 한계를 극복하기 위함이다.(Zero-injection, PureSVD)
- Group S는 user가 잘 주지 않을 것 같은 rating을 매긴다.
- Zero-injection과 pureSVD에서 imputed value를 1,2,3으로 했을 때 0보다 더 높은 정확도를 보였다.
- 즉, 0은 유저의 부정적 선호도를 너무 과장하는 값이다.
Hypothesis: 대부분의 pre-use preference는 post-use preference로 이어진다. 즉, 실제 content는 external feature(meta data)에 강하게 연관되어 있는데, 영화를 예시로 들 수 있다. 영화의 줄거리는 감독, 배우, 장르 등에 많이 영향 받는다.
Pre-use와 Post-use preference 사이의 양의 상관 관계가 있음을 확인했다. 특히 사용전 선호도가 0.2~1.0인 경우가 그랬고, 대부분의 항목(약 98%)는 0.2~1.0 범위의 속한다. 오직 pre-use preference만을 가지고 추론한 결과도 정확도가 높았다. ex) itemKNN보다 389%, SVD보다 176% 높았다.(P@5, 상위 5개)
딥러닝 기반 접근 방식도 마찬가지다. 위의 가설을 따르면서, 품목에 대한 사용자의 pre-use preference가 사용자에 따라 post-use preference로 이어지는 정도가 다를 수 있음을 유의한다.
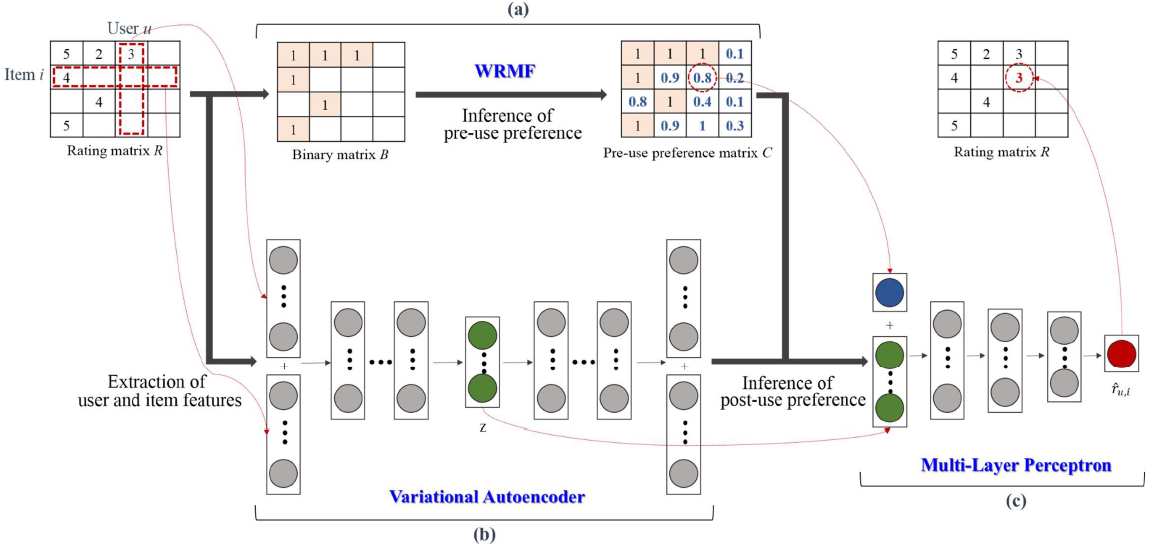
이 approach의 장점으로는, CF-agnostic하다는 것이다. 즉 어떤 CF method도 다 적용할 수 있다. 또한 앞서 말한 3 가지 claim을 모두 만족한다. Variant로는 itemKNN이나 SVD를 연계해서 구하는 방법을 생각해볼 수 있다.
