[데이터 사이언스] Data Preprocessing
in CS Review on DataScience
Chapter 3. Data Preprocessing
- Data Preprocessing: An Overview
- Data Quality
- Major Tasks in Data Preprocessing
- Data Cleaning
- Data Integration
- Data Reduction
- Data Transformation and Data Discretization
Data Quality: Why Preprocess the Data?
Data quality를 측정에 관해 다양한 차원의 관점들이 있다.
- Accuracy: 얼마나 정확한가?
- Completeness: 얼마나 데이터가 완전한가?(결측치 없고 다 사용가능한가)
- Consistency: 데이터가 일관적인가? (나이와 생년의 불일치 등)
- Timeliness: 얼마나 최근의 정보를 갖고 있는가?
- Believability: 데이터를 얼마나 신뢰할 수 있는가?
- Interpretability: 데이터를 얼마나 쉽게 이해할 수 있는가?
Major Tasks in Data Preprocessing
- Data cleaning: 결측치를 채우기, noise와 outlier 처리, inconsistencies 해결
- Data integration: 여러 DB, 데이터 큐브, 파일들 통합
- Data reduction
- Dimensionality reduction
- Numerosity reduction
- Data compression
- Data transformation and data discretization
- Normalization
- Concept hierarchy generation
Data Cleaning
- Incomplete
- Noisy
- Inconsistent
- Intentional
Incomplete(Missing) Data
데이터가 항상 사용 가능한 것은 아니다. 즉, 데이터에는 결측치들이 많이 있다.
결측치는 장비의 오작동일수도 있고, 다른 기록된 데이터와 일치하지 않아서일수도 있고, 입력하는 시점에 별로 중요하지 않은 것으로 간주되어서 입력되지 않았을수도 있고 데이터의 변경이나 기록 등을 등록하지 않을 수도 있다. 위와 같이 여러 이유들로 결측치는 존재하고 이러한 결측치들을 유추해야 한다.
이러한 결측치들은 어떻게 다뤄야할까?
일반적으로 무시한다. 분류 task 시에 class label이 누락되었다면 일반적으로 결측치는 무시한다. 그러나 이런 결측치가 많다면 당연히 성능이 좋지 않다.
또는 수동적으로 결측치들을 채운다. 이는 매우 힘들고 현실적으로 불가능한 방법이다.
자동으로 이들을 채우는 방법들이 있다. 예를 들어, “unknown”이라는 새로운 label을 만들어서 채우던가, attribute의 mean으로 대체하거나, 동일한 class에 대해 같은 attribute의 mean으로 대체하는 방법 등이 있다. 가장 가능성이 있는 방법으론, 베이지안 공식이나 decision tree등을 사용하여 추론을 하는 방법이 있다.
Noisy Data
Noise는 측정된 변수의 랜덤한 오차나 분산을 말한다. 잘못된 attribute 값들은 결함이 있는 데이터 수집 기기에 의해서 발생할 수도 있고, 데이터 입력 및 전송 문제일 수 있고 혹은 naming convention의 불일치(cm, inch)일 수도 있다.
Data cleaning이 필요한 다른 문제들론 중복 record나 inconsistent data를 꼽을 수 있다.
이러한 noisy data를 처리하는 방법엔 두 가지가 있다. 클러스터링을 통해서 outlier를 찾고 제거하는 방법이 있다. 또는 컴퓨터가 1차로 걸러낸 후, 사람이 다시 확인을 하는 것이다.
Data Integration
여러 소스로부터 데이터들을 일관된 저장소에 결합하는 것을 말한다. 이때 스키마 통합도 이루어진다(서로 다른 소스의 메타데이터 통합).
또한 Entity identification problem이 발생한다. 이는 다른 데이터 소스에서 실제로는 같은 entity가 있는 지를 확인하는 문제이다. 나아가, 다른 소스로부터 얻은 동일한 실제 entity에 대해 attribute의 값이 다를 수 있다. 실제로는 같은 것이지만.. 또는, 다른 표현이나 척도 등을 사용해서 일어날 수 있다. 때문에, 데이터 값 충돌 감지 및 해결이 필요하다.
여러 DB를 통합하는 과정에서 redundant data가 종종 생겨난다. 같은 attribute나 object가 다른 db에서 다른 이름을 갖고 있을 수 있고(object identification), 어떤 attribute가 다른 테이블의 attribute로부터 “derived”되었을 수 있다.(Derivable data, ex. 생일날과 나이)
이러한 redundant attribute들은 correlation analysis나 covariance analysis를 통해 찾아낼 수 있다.
결과적으로 integration을 조심스럽게 해야 이러한 redundancy나 inconsistency를 최소화할 수 있으며 mining 속도와 quality를 개선할 수 있다.
Correlation Analysis (Nominal Data)
| Play chess | Not play chess | Sum (row) | |
|---|---|---|---|
| Like science fiction | 250(90) | 200(360) | 450 |
| Not like science fiction | 50(210) | 1000(840) | 1050 |
| Sum (col) | 300 | 1200 | 1500 |
science fiction을 좋아하는 것과 체스를 하는 것이 서로 상관관계가 있는지를 알고 싶다고 하자.
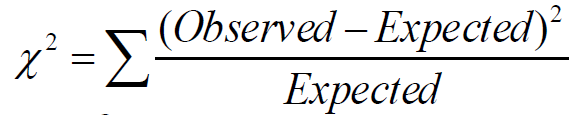
이는 Chi-square test라는 것을 통해 알 수 있다. X2값이 클수록, 변수들이 더욱 서로 상관이 있다는 것이다. 이 값에 가장 많은 기여를 하는 부분은 실제값과 예측 값이 매우 다른 항이다.
상관관계는 인과관계와 다르다. 병원의 수와 자동차 절도 건수는 상관관계가 있고, 두 개 모두 인구와 인과관계가 있다.
Chi-square 값을 위 식에 따라 구해보자.
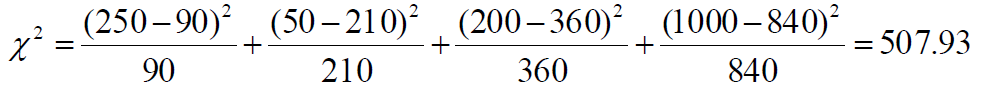
결과값이 507.93으로 sf를 좋아하는 것과 체스를 하는 것에 상관관계가 있음을 알 수 있다. (기준값이 있고 이를 충족해야 한다)
Correlation Analysis (Numeric Data)
앞선 방식은 nominal data일 경우고, Numeric data일 경우 계산 방법은 다르다. 이 때, correlation coefficient(Pearson’s product moment coefficient)를 사용하는데 식은 아래와 같다.
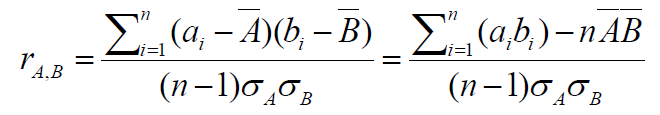
n은 tuple의 개수이고, sum(aibi)은 AB의 외적의 합을 말한다.
Correlation coefficient가 양수라면 A와 B는 양의 상관관계가 있으며 값이 클수록 더 강한 상관관계이다. 0이라면 independent이고 음수라면 음의 상관관계를 갖는다.
Covariance(Numeric Data)
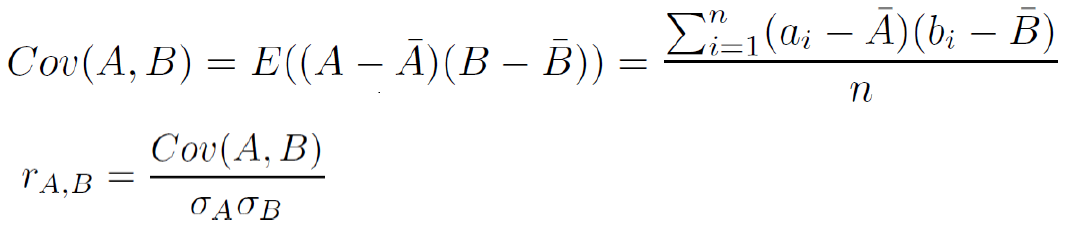
Covariance는 correlation과 비슷하다. 이 때, A 바와 B 바는 앞선 correlation에선 평균이었지만 여기서는 기댓값의 평균이다.
Covariance가 양의 값을 갖는다면, A와 B 모두 기댓값보다 큰 값을 갖는 경향이 있고, 음의 값을 갖는다면 그 반대이다. 즉, A가 기댓값보다 큰 값을 갖는다면 B값은 기댓값보다 작은 값을 갖는다. 이 역시 0이라면 independent하다.
Data Reduction
데이터 감소란 데이터셋의 축소 표현을 말한다. 크기는 훨씬 작지만 거의 동일한 분석 결과를 생성하는 것이다.
왜 축소가 필요할까? DB/data warehouse는 테라바이트의 데이터를 저장하고 이러한 데이터셋을 분석하면 매우 오랜 시간이 걸린다.
Data reduction을 하는 방법에는
- Dimensionality reduction: 중요하지 않은 attribute 제거
- Wavelet transforms, PCA(Principal Components Analysis)
- Feature subset selection, feature creation
- Numerosity reduction
- Regression
- Histograms, clustering, sampling
- Data compression
등이 있다.
Dimensionality reduction
- Curse of dimensionality: 만약 차원이 증가한다면, 데이터는 보다 더 sparse해진다. Point 사이의 밀도와 거리(clustering이나 outlier 분석에 critical한 것들)가 더 의미가 없어진다.
Dimensionality reduction은 위와 같은 “차원의 저주”를 피할 수 있으며 상관없는 feature들을 지울수도 noise를 줄일 수도 있다. 결과적으로 데이터 마이닝에 들어가는 시간 및 공간을 줄일 수 있다. 또한 더 쉽게 visualization할 수 있다.
이러한 방법엔 Wavelet transforms와 PCA 등이 있다.
1. Wavelet Transformation(Decomposition)
Wavelet이란 공간 효율적인 함수 계층적 분해를 위한 수학적 도구이다. 원어를 번역하다보니 말이 너무 어려운데 결국 공간을 효율적으로 쓰겠다는 말이다.
만약 데이터 S가 [2, 2, 0, 2, 3, 5, 4, 4]로 이루어져있다면 이를 압축하겠다는 것이다.  위 표를 보자. 우선 값을 2개씩 묶어서 평균을 구해준다. 이 때, detail coefficient는 왼쪽으로 갈땐 +, 오른쪽으로 갈땐 -를 적용해줘야한다. 즉, 2,1,4,4에서 4를 보자. 4에서 +(-1)을 해주면 3이고 -(-1)을 해주면 5이다. 그렇게 앞선 값을 복원할 수 있다. 똑같이 8개의 숫자를 8개로 변형했는데 압축은 어디서 일어날까?
위 표를 보자. 우선 값을 2개씩 묶어서 평균을 구해준다. 이 때, detail coefficient는 왼쪽으로 갈땐 +, 오른쪽으로 갈땐 -를 적용해줘야한다. 즉, 2,1,4,4에서 4를 보자. 4에서 +(-1)을 해주면 3이고 -(-1)을 해주면 5이다. 그렇게 앞선 값을 복원할 수 있다. 똑같이 8개의 숫자를 8개로 변형했는데 압축은 어디서 일어날까?
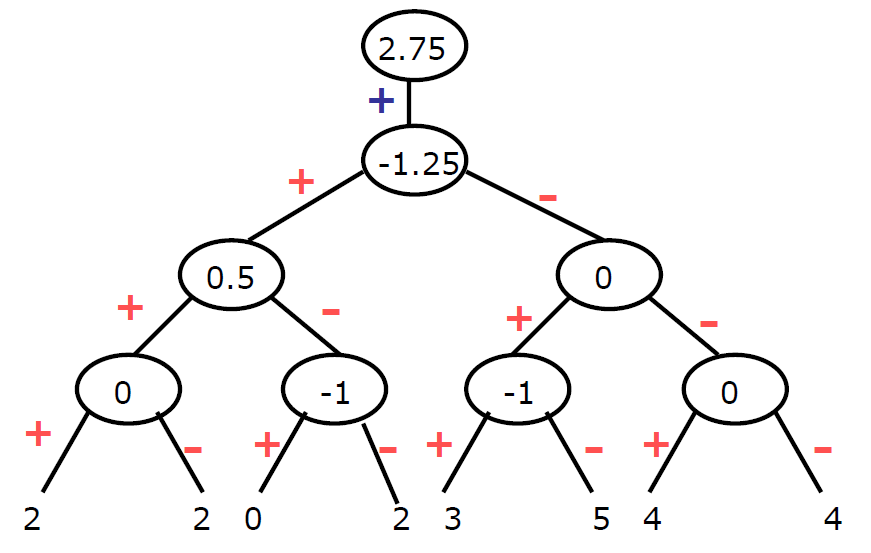 결국, 어느 level 까지 취할 것인가가 compression의 범위가 된다. 연산 상에서 마지막에 가까울수록, 즉 위의 error tree 기준으로 위 쪽에 있을수록 더 중요한 표현이 되는 것이다.
결국, 어느 level 까지 취할 것인가가 compression의 범위가 된다. 연산 상에서 마지막에 가까울수록, 즉 위의 error tree 기준으로 위 쪽에 있을수록 더 중요한 표현이 되는 것이다.
2. Principal Component Analysis (PCA)
데이터들을 더 작은 차원으로 projection하는 것으로 데이터의 차원을 감소시킨다. n개의 n차원 data vector들이 있을 때, n 이하인 k 개의 orthogonal vector(PC)들을 찾는다. 이들이 데이터를 작은 차원으로 표현하기 적절하기 때문이다.
- input data를 normalize한다: 각 attribute들을 같은 range로 제한
- k orthonormal (unit) vector들 계산한다: principal components 얻기
- 중요한 순서대로 PC들을 정렬한다.
- 중요하지 않은 것들을 우선적으로 지우면 그만큼 차원을 축소할 수 있다.
이는 numeric data에만 동작한다.
3. Attribute Subset Selection
Redundant attributes: 제품의 가격과 세금은 서로 계산하여 구할 수 있으니 중복 attribute!!
Irrelevant attributes: 학생의 gpa를 예측하는 데 id는 중요하지 않다!!
d개의 attribute가 있다면 2d-1개의 가능한 조합이 있다. 개수가 너무 많으므로 heuristic하게 정해야 하는데, 3 가지 방법이 있다.
- Significance test를 통해 고르기
- Best step-wise feature selection: 제일 좋은 attribute 택하고, 차례로 구하기
- Step-wise attribute elimination: 최악의 속성 반복적으로 제거
Numerosity Reduction
더 작은 형태의 데이터 표현을 선택하여 데이터 볼륨을 감소하는 것으로 크게 보면 parametric method와 non-parametric method가 있다.
- Parametric methods(ex. regression)
- 데이터가 어떤 모델에 fit한다고 가정
- 모델의 파라미터 추정
- 파라미터만 저장
- 가능성 있는 outlier 제외하고 데이터 버리기
- Non-parametric methods
- 어느 모델도 가정하지 않음
- Histograms, clustering, sampling 등
1. Regression Analysis
회귀 분석은 종속 변수(dependent, response variable) 및 하나 이상의 독립 변수(independent variables)로 구성된 numeric data modeling을 말한다.
파라미터들은 데이터의 best fit을 위해 추정되는데, 일반적으로 최소 제곱법으로 구한다. 이는 예측, 추론, 가설 검정 및 인과관계 모델링 등에 사용된다.
- Linear regression: (Y = wX + b)
- 직선에 fit하도록 모델링
- 종종 최소 제곱법 사용
- Multiple regression: (Y = b0 + b1X1 + b2X2)
- 종속 변수 Y를 둘 이상의 독립 변수로 이루어진 선형 함수를 통해 모델링한다.
- Nonlinear regression: (Y = b0 + b1X + b2X2)
- X1과 X2을 각각 X와 X2으로 대체하여 바꿀 수 있다.
2. Histogram Analysis
데이터들을 버켓으로 나누고 각 버켓마다 count를 저장한다. Partitioning rule로는 Equal-width와 Equal-frequency가 있다. Equal-width는 bucket range를 동일하게, 후자는 depth를 동일하게 가져가는 것이다.
3. Clustering
유사성에 따라 데이터셋을 클러스터로 분할하는 방법으로, centroid나 diameter같은 것으로 cluster representation만을 저장한다. 계층적 클러스터링을 가질 수 있으며 다차원 인덱스 트리 구조에 저장될 수 있다.
4. Sampling
샘플링이란 전체 데이터 집합 N을 대표하는 작은 샘플 집합 획득하는 것으로 데이터 크기에 따라 잠재적으로 하위 선형인 마이닝 알고리즘을 실행할 수 있게 한다. 핵심 원칙으로 데이터의 대표적인 부분 집합을 선택해야 하며 단순 무작위 샘플링은 왜곡된 데이터가 있는 경우 성능이 매우 저하될 수 있다. 샘플링이 DB I/O 자체를 줄일 수는 없다.
- Simple random sampling
- Sampling without replacement: 중복 없이 샘플링
- Sampling with replacement: 중복 있이 샘플링
- Stratified sampling: skewed data를 핸들링하기 위함, distribution 반영하여 균등하게 샘플링
Data Compression
- String compression: 광범위한 이론과 잘 조정된 알고리즘이 있고 일반적으로 무손실이다.
- Audio/video compression: 일반적으로 손실 압축이다.
- Time sequence: 일반적으로 짧고 시간에 따라 천천히 변화한다.
- Dimensionality and numerosity reduction
Data Transformation and Data Discretization
지정된 attribute의 전체 값 집합을 새로운 replacement 값 집합에 매핑합니다. 각 이전 값을 새 값 중 하나로 식별해야 한다.
Methods
- Normalization: 더 작고 지정된 범위에 포함되도록 척도화됨
- min-max normalization
- z-score normalization
- normalization by decimal scaling
- Discretization: Concept hierarchy climbing
- Binning
- Equal-width(distance) partitioning
- Equal-depth(frequency) partitioning
Normalization
1. Min-max normalization: to [new_minA, new_maxA]
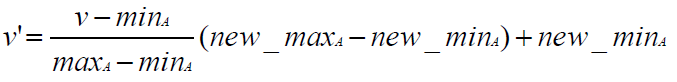
2. Z-score normalization
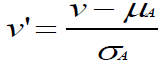
3. Normalization by decimal scaling
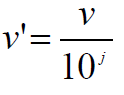
이 때, j는 MAX(abs(v’)) < 1을 만족하는 가장 작은 정수
Discretization
Continuous attribute의 범위를 interval로 나누는 것을 말한다. Label들은 실제 데이터 값을 바꾸기 위해 구간에 할당되며, 데이터의 크기가 감소하고 유사한 값이 동일해진다. 분류와 같은 추가 분석에 사용된다.
Simple Discretization: Binning
Equal-width(distance) partitioning
범위를 동일한 크기의 N개 구간으로 나눈다.(=uniform grid)
A와 B가 어떤 attribute의 가장 낮은 값과 가장 높은 값인 경우, 간격의 폭은 W = (B – A)/N이 된다. 가장 간단한 방법이라 몇 가지 문제가 있다. Outlier가 presentation을 지배할 수 있으며 치우친 데이터가 제대로 처리되지 않는다.Equal-depth(frequency) partitioning
범위를 N개의 구간으로 나누는데, 각 구간은 거의 동일한 수의 표본을 포함한다. 데이터 확장에 좋다.
- Partition into equal-frequency(equi-depth) bins
- Smoothing by bin means(평균으로 바꾸기)
- Smoothing by bin boundaries(각 끝값에 가까운 값으로 바꾸기)
