[데이터 사이언스] Social Network Analysis
in CS Review on DataScience
Chapter 9. Social Network Analysis
- Social Network Introduction
- Social Network Generation
- Mining on Social Network
Individual을 node로, social relationship을 link로 표현할 수 있다. Social network란 많은 개인들이 서로 다양한 사회적 상호작용을 하는 것을 말한다.
Social network의 예로, communication network를 말할 수 있는데 이는 많은 non-identical한 components(컴퓨터, 라우터, 위성 등)들이 서로 다양한 연결(전화선, tv선, 통신선 등)을 하고 있는 것을 말한다.
Some Interesting Quantities
- Connected components: 얼마나 많고, 얼마나 큰가?
- Network diameter: 가장 먼 두 노드의 shortest path는? 그 때, edge의 수는?
- Clustering: 어느 정도로 cluster가 local하게 연결되어 있는가? long-distance connection은 얼마나 있는가?
- Degree distribution: 노드가 평균적으로 갖고 있는 edge의 수는?
일반적으로 network는
- A few connected components(어떤 path로 웬만하면 노드끼리 도달 가능하다)
- Small diameter(약 6단계 정도로 매우 작고 logarithmical하게 증가한다)
- High degree of clustering(local하게 잘 묶인다)
- Heavy-tailed degree distribution(Edge가 많은 노드가 꽤 존재한다)
의 모습을 보인다.
Models of Social Network Generation
1. Random Graphs: 전체 노드들 중에서 랜덤하게 edge가 생성되어 모델이 만들어진다는 말이다.
2. Scale-free Networks: Power law 분포를 따르는 모델
WWW 문서들을 노드라고 하고 하이퍼링크를 링크라고 했을 때 8억 개의 documents를 조사하였더니 그 결과는 power law 분포를 따랐다. 예상은 normal distribution이었지만.. 결과적으로 WWW는 scale-free network이다.
Scale-free network 모델에서는 노드의 수가 고정되어 있다고 가정하지 않고 지속적으로 확장된다고 가정한다. 또 attachment가 uniform하지 않다고 가정한다. in-link에 비례해서 link가 생긴다고 생각하기 때문이다. 이러한 두 가지 특성이 scale free network를 만든다고 한다.
- Hyperlinks on the web
- Internet backbone
- Actor connectivity
- Science Citation Index
Robustness of Random vs. Scale-Free Networks
Random network를 랜덤하게 공격할 경우 혹은 failure가 발생할 경우 전체 네트워크가 끊어질 가능성이 높지만 scale-free network는 그렇지 않다. 반면, 랜덤하게 공격하지 않고 hub를 집중적으로 공격하거나, hub에서 failure가 발생할 경우 scale-free network 또한 네트워크가 끊어질 가능성이 높다. 결과적으로 hub를 잘 지켜야 네트워크를 잘 지킬 수 있다.
Information on the Social Network
서로 다르고, 다양한 관계를 갖는 데이터가 그래프 또는 네트워크로 표현된다.
노드는 object이고 각기 다른 종류의 object를 가질 수 있으며, object들은 attribute들을 가지며, label 또는 class가 있을 수 있다.
Edge들은 link이며 다른 종류의 link를 가질 수 있으며, 역시 attribute들을 갖는다. 또한, link들은 방향이 지정될 수 있으며 binary일 필요는 없다(weight이 있을 수 있음).
Link들은 object간의 관계나 상호작용을 표현한다. 이러한 것들은 mining을 더욱 풍부하게 만든다.
What is New for Link Mining Here
기존의 머신러닝 및 데이터 마이닝은 하나의 관계에서 얻은 같은 종류의 객체들을 대상으로 했었다. 그러나, 실제 세계의 데이터셋은 다중 관계, 서로 다른 종류, semi-structured(like webpage, 형태가 딱히 정해져 있지 않음) 등으로 구성되어 있다. 이 때문에, Link mining과 social network analysis는 새롭게 부상하는 연구 분야가 되었다.
A Taxonomy of Common Link Mining Tasks
- Object-Related Tasks
- Link-based object ranking
- Link-based object classification
- Object clustering (group detection)
- Link-Related Tasks
- Link prediction
- Graph-Related Tasks
- Subgraph discovery
- Graph classification
- Generative model for graphs
What is a link in link mining?
링크란 데이터 간의 관계로 link를 가지는 network에는 Homogeneous와 heterogeneous로 두 가지 종류가 있다.
Homogeneous는 단일 object type과 단일 link type을 갖으며, 단일 모델이다. 예로 친구 네트워크(사람과 친구관계만 있음)나 linked Web page들의 집합인 WWW를 들 수 있다.
Heterogeneous는 다중 object type과 link type을 갖으며, 예로 medical network(환자, 의사, 질병, 치료)나 bibliographic network(출판물, 저자, 발표 장소)을 들 수 있다.
Link-Based Object Ranking(LBR)
LBR은 그래프의 링크 구조를 잘 분석하여 그래프 내의 object 집합의 순서를 중요도에 따라 지정하거나 우선순위를 지정하는 것이다. 이를 통해 단일 object type과 단일 link type을 갖는 그래프에 집중하는 것이다. 예로, web Information analysis를 들 수 있는데, HITS나 PageRank가 전형적인 LBR 접근 방식이다.
HITS: Capturing Authorities & Hubs
하이퍼링크는 일종의 참조를 말하는데, 많은 페이지들에 의해 참조되는 페이지를 “good Authorities”라고 하며, 또한 많은 페이지들을 가리키는 페이지를 “good hubs”라고 한다.
HITS의 key idea는 “good Authorities”는 “good hubs”들이 가리킬 것이고, “good hubs”는 “good Authorities”들을 가리킬 것이라는 것이다. 즉, 좋은 hub가 가리키면 좋은 authority가 되는 것이고, 좋은 authority들을 가리키면 좋은 hub가 되는 것이다. 이 관계는 결국 상호 강화하는 관계이다(=iterative mutual reinforcement).
각 페이지(di)는 두 가지 score를 갖는다. Hub score(=h(di))와 Authority score(=a(di))이다.
Hub score는 해당 페이지의 out-link neighbor들의 authority score들의 합이고, authority score는 반대로 해당 페이지의 in-link neighbor들의 hub score들의 합이다.
초기값은 hub score, authority score 모두 1로 초기화하고, hub score부터 계산해준다. 이후, authority score를 계산하고 두 값 모두 normalize를 해준다. Normalize는 각각의 score들의 제곱의 합이 1이 되게 만든다. 이를 수렴할때까지 반복해주면 된다.
PageRank: Capturing Page Popularity
자주 인용되는 페이지는 일반적으로 더 중요하다고 볼 수 있다. PageRank는 기본적으로 citation counting이지만 그저 counting하는 것 이상의 효과를 보인다. “Indirect citations”를 고려하는데 이는 많이 인용된 paper가 인용하는 것은 더 큰 의미가 있다는 것을 뜻한다. 또한, 모든 page의 인용 횟수가 0이 아닌 것으로 가정(smoothing of citation)한다.
1. Indirect Citation
“중요한(important)” 페이지는 다른 많은 페이지들이 참조하는 것을 말하며 특히 많은 중요한 페이지들이 참조한다면 더욱 중요한 것이다. Counting만 고려하는 것이 아니라 간접적인 정보도 활용하는 것이다.
2. Calculate importance score (authority score)
앞선 HITS와 달리 PageRank에서는 authority score로 authority score를 구한다. 즉, importance score를 구한다.
처음에는 모든 페이지에 같은 스코어(e.g. 1)를 할당한다.(=smoothing of citation)
각 페이지마다, out-link를 따라서 그 이웃들에게 해당 페이지의 스코어를 분할해서 전달한다. 이 때, 해당 페이지의 점수가 변하지는 않는다. 그렇게 전달 받은 점수들은 in-link를 통해 각 페이지에 전해질 것이며 그를 모두 더한다. 위 과정이 수렴이 될 때까지 반복하면 importance score가 정해진다.
하지만 위와 같은 simple한 version은 2 가지 문제가 발생한다. Dangling nodes와 Cyclic citation이다.
Dangling nodes는 어떤 페이지가 out-link가 없고 그 페이지로 in-link들만이 구성되어 있다면, 그 페이지로 점수가 계속 전해져서 결국 그에 연결된 다른 페이지들은 점수를 잃는 현상이다.
Cyclic citation은 일련의 페이지들이 cycle을 형성해서 점수가 안 빠져나가고 고이게 된다. 계속 더해주어서 점수가 무한이 되는 것을 말한다.
이를 어떻게 해결할 수 있을까?
먼저 dangling nodes 부터 살펴보자. Out-link가 없는 페이지는 해당 iteration에서 다른 모든 노드의 문서들에게 점수를 균등하게 분할해서 나눠주는 형식으로 처리하면 해결할 수 있다.
Cyclic citation의 경우 alpha의 확률로는 똑같이 out-link를 따라 진행하고 (1-alpha)의 확률로 다른 모든 노드에게 균등하게 점수를 분할하는 방식으로 처리해서 해결하였다.
3. Random Surfer
말 그대로 웹을 랜덤하게 서핑하는 것이다. 기본적으로, 현재 연결된 링크들 중 랜덤하게 골라서 서핑하는 것이다.
또는. 랜덤한 페이지로 jump하는 것을 말하며 다른말로 restart surfing이라고도 한다.
어떤 임의의 페이지에서 alpha의 확률로 out-link를 랜덤하게 선택해서 진행하고(=random walk, dangling node들에 대해서는 다른 노드들로의 edge를 만들어주고 random walk을 진행한다), (1-alpha)의 확률로 랜덤한 페이지로 간다.(=restart)
이렇게 경로와 상관없이 랜덤하게 흩뿌려주는 과정 때문에 random surfing이라는 말이 붙었다.
이를 수식으로 표현하면 아래와 같다.
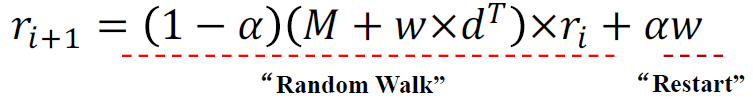
초기의 r0은 전부 1을 할당해도 되고, 1/n값으로 할당해도 된다. 같은 값으로 초기화만 하면 된다. 위 식에서는 random walk에 (1-alpha)가 곱해져 있는데 딱히 상관없다. ri와 ri+1의 차이가 미미할 때까지, 즉 수렴할때까지 반복하면 된다.
결국, random walk는 dangling nodes 문제를 해결했고, restart는 cyclic citation을 해결한 셈이다.
Link-Based Object Classification (LBC)
앞에서는 object의 attribute로 예측했었는데, 이제는 그 뿐 아니라 그의 link와 그 link로 이루어진 object의 attribute까지 고려하는 것이 LBC이다.
예로,
- Web: 페이지에 나타나는 단어, 페이지 간의 링크, HTML 태그 등을 기준으로 웹 페이지의 카테고리를 예측
- Citation: 단어 발생, 인용, 공동 인용을 기반으로 논문의 주제를 예측
- Epidemics: 감염환자의 특성에 따라 질병 유형 예측
결과적으로, 하나의 attribute만으로 판단하기 보다 여러 것을 복합적으로 보고 판단하는 것이 더 정확도가 높을 것이라는 것이 idea이다.
Group Detection
그래프에 있는 노드들을 클러스터화하는 것이다. 앞서 배운 클러스터링과 비슷한 task이다.
Methods
- Hierarchical clustering
- Blockmodeling of SNA
- Spectral graph partitioning
- Stochastic blockmodeling
- Multi-relational clustering
Community 안에서 Edge들이 충분하고 community 간의 edge들이 별로 없다면 쉽게 할 수 있겠지만 그렇지 않은 경우 어렵다.
Link-Related Tasks
Link Cardinality Estimation
어떤 object를 가리키는 link의 수를 예측하는 것이다.
또는, 특정 object에서 경로를 따라 도달한 object 수를 예측하는 것일 수도 있다.
Link Prediction
두 개의 object 사이에 link가 존재할 것인가에 대해 예측하는 것이다.
Graph-Related Tasks
Subgraph Discovery
- Find characteristic subgraphs
- 그래프 기반 데이터 마이닝에 초점
- Application
- Biology: 단백질 구조 발견
- Communications: 합법 vs 불법적 그룹
- Chemistry: 화학적 substructure 발견
- Method
- Subgraph pattern mining
- Graph classification
- 서브그래프 패턴 분석에 따른 분류
