[분산 컴퓨팅] Chapter 1. Introduction
in CS Review on Distributedcomputing
2022년 2학기 “분산 컴퓨팅” 수업을 듣고 요약한 내용입니다.
본 수업에서 다루게 될 내용
- Concepts and basics of distributed computing
- Microservice architecture(MSA)
– Container-based and microservice-based cloud applications
– Docker and Kubernetes
– Hands-on experience with container platforms - Blockchain network protocol and application
– Basics of Bitcoin protocol
– Distributed consensus algorithms
– Ethereum and smart contract
과제
- Kind tutorial
Chapter 1: Introduction
- What is a distributed system?
- Characteristic 1: Collection of autonomous computing elements
- Characteristic 2: Single coherent system
- Middleware and distributed systems
- Design goals
- Supporting resource sharing
- Making distribution transparent
- Being open
- Being scalable
- Pitfalls
- Types of distributed systems
- High performance distributed computing
- Distributed information systems
- Pervasive systems
- Summary
1. What is a distributed system?
Distributed system이란 무엇인가? 한글로는 분산 시스템이라고도 하는데, 사용자에게 단일한 coherent system으로 비춰지는 autonomous computing elements들의 집합이라고 할 수 있다.
Autonomous computing elements는 독립적인 하드웨어 장치나 소프트웨어 프로세스를 말하며 노드라고도 한다.
그럼 Coherent system는 무슨 소리일까?
전체 동작 방식에 거스르지 않고 자연스러운 컴포넌트들로 이루어진 일관성 있는 시스템을 말한다. 이런 일관성을 위해 노드들은 긴밀히 통신해야 한다.
Collection of autonomous nodes
일관적인 시스템을 위해 노드들은 통신해야 하는데 한 가지 문제가 있다. 각 노드들은 자율적이기에 독립적인 clock을 가지고 있다. 즉, global한 clock이 없다 보니 기본적인 동기화나 협력하기가 어렵다!! 예를 들어, Node A가 Node B에 오후 1시에 보낸 메시지를 B는 오후 12:30분에 수신되었다고 로그를 해석할 수도 있다.
결과적으로, 이러한 노드들의 통신을 위해 관리하는 방법이 필요해졌다.
Overlay Network
오버레이 네트워크의 가장 잘 알려진 예시는 p2p system이고, 오버레이 네트워크의 유형으로는 structured와 unstructured가 있다.
Structured는 tree나 ring처럼 각 노드는 인접 노드 집합을 가지고 있고(토폴로지가 정해진 상황), unstructured는 각 노드가 무작위로 선택된 다른 노드에 대한 참조를 가진다(random 토폴로지, 랜덤한 이웃을 가짐).
더 자세한 것은 chapter 2에서 살펴보자.
Single Coherent System
사용자와 시스템 간의 상호 작용이 어디서, 언제, 어떻게 이루어지는지에 관계없이 노드들은 전체적으로 동일한 방식으로 작동한다.
End-user는 어디에서 computation이 일어나는지 알 수 없고 데이터가 정확히 저장되는 곳(애플리케이션과도 무관)이 어디인지, 또한 데이터가 복제되었는지조차 알 수 없다. 사실 end-user는 위 내용들을 알 필요도 없다.
이를 다른 말로 distribution transparency라고 한다.
이를 완전하게 달성하는 것은 매우 어렵다. Design goals에서 더 살펴보자.
Middleware: the OS of distributed systems
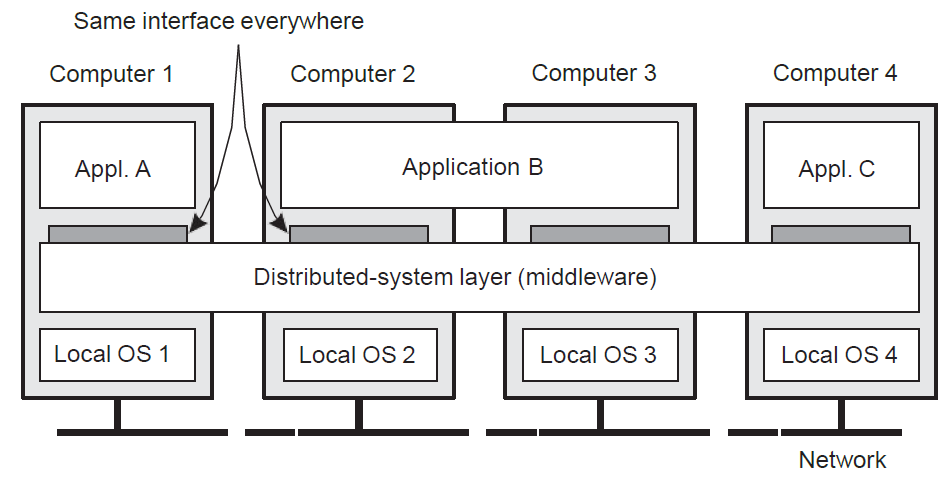
미들웨어는 위의 그림처럼 여러 computer에서 OS와 application 사이에 걸친 layer로 분산시스템의 인터페이스라고 할 수 있다. 미들웨어는 애플리케이션에서 별도로 구현할 필요가 없는 일반적으로 사용되는 컴포넌트 및 함수를 갖고 있다.
그림에서 컴퓨터들의 OS가 각각 다른데, 분산 시스템을 구성하는 컴포넌트는 heterogeneous할 수 있으므로 하드웨어나 OS가 다를 수 있다. 각 컴퓨터의 OS가 다르더라도 미들웨어의 도움을 받아 서로 다른 세 애플리케이션의 interaction이 가능해진다.
미들웨어라는 중간에 위치한 레이어를 통해 분산 시스템의 목적 중 하나인 “분산된 사실을 숨기는 것”이 가능해진다. 미들웨어 밑에 분산되어있는 컴포넌트들끼리 필요한 프로세싱, 커뮤니케이션 같은 것들을 미들웨어에서 처리한다. 이런 식으로 분산 시스템의 resource manager 역할을 한다. 컴퓨터에게 OS가 분산시스템에겐 미들웨어라고 할 수 있다.
한 가지 운영 체제와의 주요 차이점은 미들웨어 서비스가 네트워크 환경에서 제공된다는 것이다.
미들웨어 서비스의 예시
- session & presentation layer
- TP monitor
- Communication: RPC
- Transaction
- Service composition: Web services
2. Design goals
1. Sharing resources: 자원을 공유하고 쉽게 이용할 수 있게 해야 한다.
대표적인 예시로 다음을 들 수 있다.
- 클라우드 기반의 공유 스토리지 및 파일
- P2P 지원 멀티미디어 스트리밍
- 공유 메일 서비스
- 공유 웹 호스팅
2. Distribution transparency: 리소스가 네트워크를 통해 분산된다는 사실을 사용자로부터 숨겨야 한다.
single coherent system을 위해 아래와 같은 것들을 지원해야 한다.
- Access: 데이터 표현의 차이 및 object 접근 방법 숨기기
ex) 빅-엔디안, 리틀-엔디안 아키텍처 차이, 경로와 같은 것도 슬래시/백슬래시 고민할 필요 없게 해준다. - Location: object의 물리적 위치 숨기기 ex) URL
- Relocation: object를 사용 중에 다른 위치로 이동할 수 있도록 숨긴다.
ex) 모바일 유저의 엑세스 포인터 변경 - Migration: object가 다른 위치로 이동할 수 있도록 숨긴다.(리소스의 이동 여부 숨기기)
- Replication: object가 복제되는 것을 숨긴다.
ex) mirrored site로 자동으로 redirect 된다. - Concurrency: object를 여러 독립 사용자가 공유할 수 있음을 숨긴다.
- Failure: object의 오류 및 복구를 숨긴다.
하지만 시스템에 따라 위의 transparency들을 모두 지키는 것은 바람직하지 않다. 또한 모두 지킬 수 없을 수도 있다.
숨길 수 없는 물리적인 통신 지연이 있을 수 있고, 네트워크 및 노드의 failure들을 완전히 숨기는 것은 이론적으로나 현실적으로도 불가능하기 때문이다. 예시로, 느린 컴퓨터와 crashed 컴퓨터를 구분할 수 없으며, crash 전에 서버가 실제로 작업을 수행했는지 확인할 수 없는 등을 예로 들 수 있다.
완전한 transparency로 인해 성능이 저하되고 시스템 분포가 노출될 수 있다. (Master를 통해 복제본을 정확하게 최신 상태로 유지하려면 시간이 걸리고, falut tolerance를 위해 쓰기 작업 즉시 플러시를 하는 등)
때때로, distribution을 노출하는 것이 좋을 수 있다.
- 위치 기반 서비스 활용(인근 친구 찾기)
- 다른 시간대의 사용자를 처리할 때(내 시간대에 따라 조간신문 서비스)
- 사용자가 상황을 더 쉽게 이해할 수 있는 경우(서버가 오랫동안 응답하지 않을 경우, 고장으로 보고)
결과적으로는… case by case로 알잘딱깔센으로 하라는 뜻이다..
3. Openness: 분산 시스템이 open되어야 한다.
기본 환경에 관계없이 다른 개방형 시스템의 서비스와 상호 작용할 수 있어야 한다.
- Systems should conform to well-defined interfaces: 컴포넌트가 제공하는 기능의 definition이 interface에 맞게 제공해야 한다.
- Systems should easily interoperate(상호 운용성): 누구에 의해 컴포넌트가 구현되었든, 상호 간에 동작(interface 지킨다)해야 한다.
- Systems should support portability(이식성) of applications: A env에서 동작하는 app이 B env에서도 동작해야 한다.
Systems should be easily extensible(확장성): 컴포넌트 추가 및 대체가 용이해야 한다.
- Policies vs. Mechanisms
- Policy는 어떤 방식으로 서비스할지, 즉 설정을 뜻하고 Mechanisms은 그 구현체를 말한다.
- Openness를 구현하는 예시로 두 가지의 차이를 알아보자.
- 정책의 예시: config, setting
- 클라이언트-캐시 데이터에 대해 어느 정도의 일관성이 필요한가?
- 다운로드한 코드가 수행할 수 있는 작업은 무엇인가?
- 대역폭이 다양한 상황에서 조정해야 하는 QoS 요구사항은 무엇인가?
- 커뮤니케이션을 위해 어느 정도의 secrecy가 필요한가?
- 메카니즘의 예시: policy를 구현한 code, implementation
- 캐싱 정책 설정 허용
- 모바일 코드에 대한 다양한 신뢰 수준 허용
- 데이터 스트림당 조정 가능한 QoS 매개 변수 제공
- 다양한 암호화 알고리즘 제공
- 정책의 예시: config, setting
4. Scalability: 분산 시스템은 확장 가능해야 한다.
- Scale in distributed systems
- Size scalability: 사용자와 프로세스의 수
- centralized(한 자리에서 서버 동작) 해결책의 한계
- CPU에 의해 제한된 계산 용량
- CPU 간 전송 속도를 포함한 스토리지 용량 및 디스크
- 사용자와 중앙 집중식 서비스 간의 네트워크
- centralized(한 자리에서 서버 동작) 해결책의 한계
- Geographical scalability: 노드들의 최대 거리
- 단순히 LAN에서 WAN으로 이동할 수 없음
- 많은 분산 시스템은 동기화된 클라이언트-서버 상호 작용을 가정하는데 LAN은 수백 마이크로 세컨드의 지연 시간을 갖고 WAN은 수백 밀리 세컨드의 지연시간을 가져서 이동하기 쉽지 않다.
- WAN 링크는 종종 본질적으로 신뢰할 수 없다
- 멀티포인트 통신이 부족하여 간단한 검색 브로드캐스트를 할 수 없다
- 솔루션은 별도의 이름 지정 및 디렉터리 서비스(자체적인 확장성 있음)를 개발
- 단순히 LAN에서 WAN으로 이동할 수 없음
- Administrative scalability: Administrative domain의 수
- 다른 도메인들을 거치면서 문제 발생!
- Computing grids: 서로 다른 도메인의 값비싼 리소스 공유
- Shared equipment: 대규모 공유 센서 네트워크로 제작된 전파 망원경 등
- 예외) P2P networks
- File sharing systems(e.g. BitTorrent)
- P2P telephony (Skype)
- Peer-assited audio streaming(Spotify)
- Size scalability: 사용자와 프로세스의 수
Techniques for scaling
1. Hide communication latencies
- Asynchronous communication: function, routine(callback, listener)
- Separate handler for incoming response
- 서버에서 계산할 것을 클라이언트에서 계산하게 하여 시간 단축!
- 웹 브라우저 computation module(java applets)
2. Partition data and computations across multiple machines
- Move computation to clients(Java applets)
- Decentralized naming services(DNS)
- Decentralized information systems(WWW)
3. Replication and caching: Make copies of data available at different machines
- Replicated file servers and DB
- Mirrored Web sites(service provider가 사전에 replicated)
- Web caches(in browsers and proxies)
- File caching(at server and client)
The problem with Replication
여러 복사본(캐시 또는 복제된 복사본)이 있으면 불일치가 발생한다. 한 복사본을 수정하면 해당 복사본이 다른 복사본과 달라지게 된다. 복사본을 항상 일관되고 일반적인 방식으로 유지하려면 각 수정에 대한 global synchronization이 필요해진다.
불일치를 허용할 수 있다면 글로벌 동기화의 필요성을 줄일 수 있다.
Developing distributed systems: 간과하기 쉬운 점들!
많은 분산 시스템은 실수들로 인해 불필요하게 복잡하다. 결과적으로 많은 잘못된 가정을 하게 된다.
- 네트워크를 신뢰할 수 있다.
- 네트워크가 안전하다.
- 동형의 네트워크이다.
- 토폴로지가 변경되지 않는다.
- Latency가 0이다.
- 대역폭이 무한이다.
- Transport cost가 0이다.
- Administrator가 하나이다.
3. Types of distributed systems
1. High performance distributed computing systems: 컴퓨팅 파워를 필요로하는 서비스를 요청할 때 사용
2. Distributed information systems: 네이버 클라우드처럼 정보를 제공해주는 시스템
3. Distributed systems for pervasive computing: 다이나믹한 환경에서 사용자가 언제 어디서든 제공 받을 수 있는 분산 시스템
Multiprocessor and multicore vs. Multicomputer
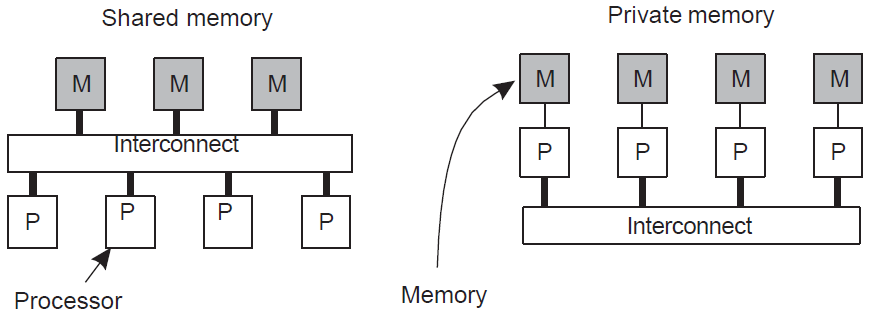
Multi-processor는 memory를 공유하고 processor간의 관계가 동등하지 않을 수 있는 반면 multi-computer는 독자적인 메모리를 갖으며 별개의 machine으로 봐야 한다.
멀티프로세서는 멀티컴퓨터에 비해 상대적으로 프로그래밍이 쉽지만 프로세서(또는 코어)의 수를 늘릴 때 문제가 있다. 이를 다중 컴퓨터 위에 공유 메모리 모델을 구현하여 해결할 수 있다.
가상 메모리 기술을 통한 예로, 서로 다른 프로세서의 모든 기본 메모리 페이지를 하나의 가상 주소 공간에 매핑한다. 프로세서 A의 프로세스가 프로세서 B에 위치한 페이지 P에 주소를 지정하면, P가 로컬 디스크에 위치했을 때와 마찬가지로 A의 OS가 P를 트랩하고 B에서 가져옵니다.
분산 공유 메모리의 성능은 멀티프로세서의 성능과 경쟁할 수 없었고 프로그래머들의 기대를 충족시키지 못했다. 결과적으로 버려졌다.
Cluster computing
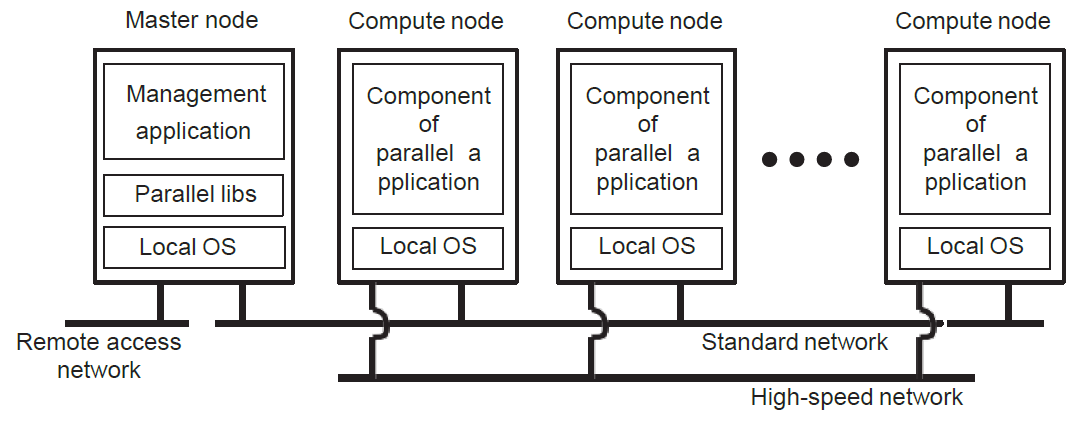
기본적으로 LAN을 통해 연결된 하이엔드 시스템 그룹(물리적으로 근처에 배치)으로 동일한 OS를 사용하며 거의 동일한 하드웨어를 사용한다. 또한 단일 관리 노드(master, 그 외에는 모두 slaves)를 가진다. slave들 간에는 high-speed network를 사용하고 전체적으론 standard network를 사용한다.
Grid computing
모든 곳에서 많은 노드 제공를 받는다. 당연히 heterogeneous하며, 여러 조직으로 분산된다. 또한 WAN을 쉽게 확장할 수 있다. 예로, SETI@home이나 folding@home을 들 수 있다.
협업을 허용하기 위해 그리드는 일반적으로 가상 조직을 사용하는데 본질적으로, 이것은 리소스 할당에 대한 권한을 허용하는 사용자(또는 더 나은 사용자 ID)의 그룹이다.
Grid computing의 아키텍처는 다음과 같다. 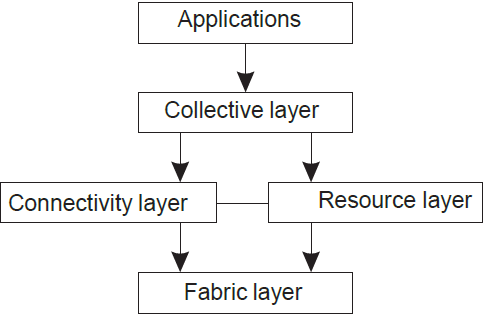
- Fabric: 로컬 리소스에 대한 인터페이스를 제공(상태 및 기능 쿼리, 잠금 등)
- Connectivity: 리소스 간 데이터 이동을 위한 통신/트랜잭션 프로토콜 또는 다양한 인증 프로토콜.
- Resource: 프로세스 생성 또는 데이터 읽기 등 단일 리소스를 관리
- Collective: 검색, 스케줄링, 복제와 같은 여러 리소스에 대한 액세스를 처리
- Application: 단일 조직에 실제 그리드 응용 프로그램을 포함
Cloud computing
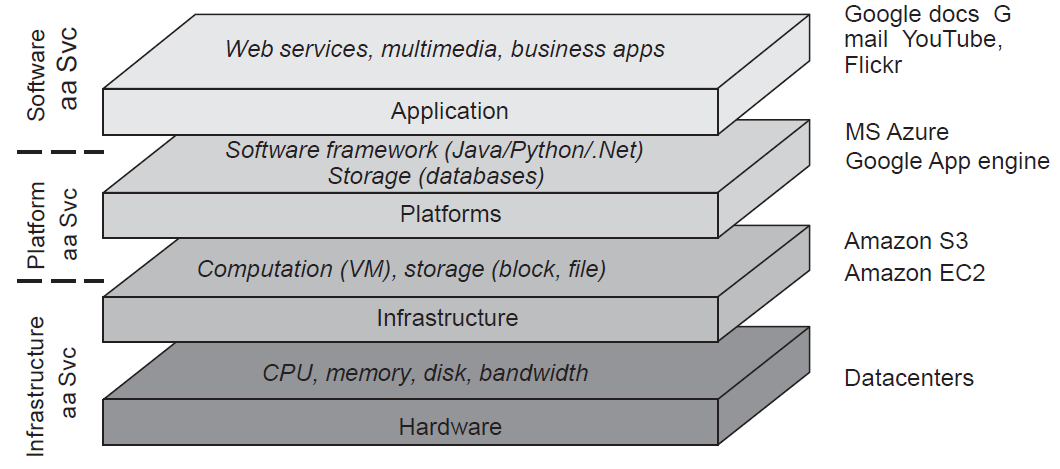
- Hardware: 프로세서, 라우터, 전원 및 냉각 시스템
- Infrastructure: 가상화 기술을 구현, 가상 스토리지 장치 및 가상 서버 할당 및 관리를 중심으로 발전
- Platform: 스토리지 등에 대한 상위 수준의 추상화를 제공 ex) Amazon S3 스토리지 시스템은 이른바 버킷에 정리되고 저장될 (로컬 생성) 파일에 대한 API를 제공
- Application: 오피스 제품군(텍스트 프로세서, 스프레드시트 애플리케이션, 프레젠테이션 애플리케이션)과 같은 실제 애플리케이션, OS와 함께 제공되는 애플리케이션 제품군과 비교 가능
상호 운용성은 어떻게 달성할까? 기본적인 접근법은 다음과 같다.
네트워크 애플리케이션은 원격 클라이언트가 서비스를 사용할 수 있도록 서버에서 실행되는 애플리케이션이다.
- 단순한 통합: 클라이언트는 (다른) 애플리케이션에 대한 요청을 결합하고, 요청을 보내고, 응답을 수집하고, 사용자에게 일관된 결과를 제공합니다.
- 다음 단계: 애플리케이션 간 직접 통신을 허용하여 EAI(Enterprise Application Integration)으로 이어집니다.
Distributed transactions
Transaction의 primitive는 5가지가 있다.
- BEGIN_TRANSACTION
- END_TRANSACTION
- ABORT_TRANSACTION
- READ
- WRITE
DB 수업에서 배웠듯 transaction은 항상 all-or-nothing(atomic)이다. 또한 다음과 같은 특징을 갖는다.
- Atomic
- Consistent
- Isolated
- Durable
TPM: Transaction Processing Monitor
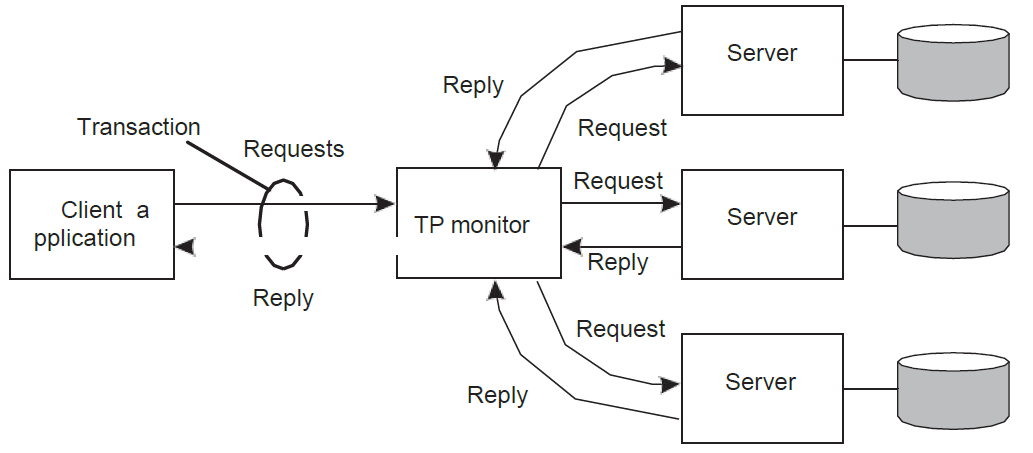
많은 경우, 트랜잭션에 포함된 데이터는 여러 서버에 분산된다. TP 모니터는 트랜잭션 실행을 조정하는 역할을 한다. 즉, TPM은 distributed information system이라고 할 수 있다.
Middleware and EAI
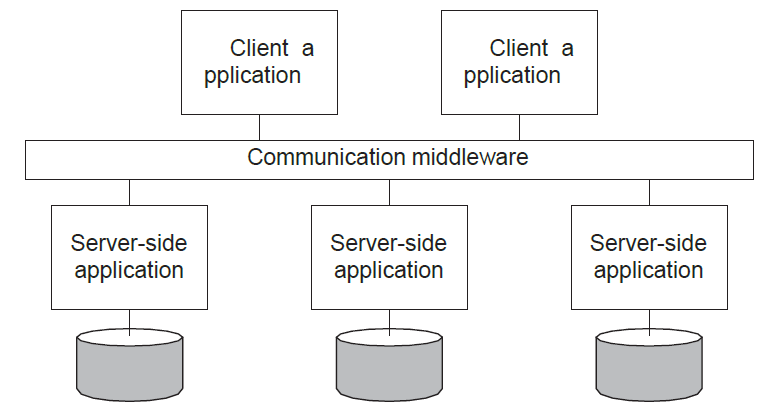
미들웨어는 통합을 위한 통신 기능을 제공한다.
- Remote Procedure Call(RPC, RMI): 요청은 로컬 프로시저 호출을 통해 전송되고, 메시지로 포장되고, 처리되고, 메시지로 응답되며, 호출에서 반환되는 결과로 반환된다. Procedure는 함수라고 생각하면 된다.
- Message Oriented Middleware(MOM): 메시지가 논리적 연락처로 전송되고(게시됨) 등록된 응용 프로그램으로 전달됩니다. ex) rabbitMQ / activeMQ / PubSUb
How to integrate applications
- File transfer: 기술적으로 간단하지만 유연하지 않음
- 파일 형식 및 레이아웃 파악
- 파일 관리 파악
- 전파 업데이트 및 알림 업데이트
- Shared DB: 훨씬 더 유연하지만 병목 현상의 위험과 함께 공통 데이터 체계가 필요
- RPC: 일련의 작업을 실행해야 할 때 효과적이지만 동시 수행중이어야 하는 제약이 있음
- Messaging: RPC를 사용하려면 발신자와 발신자가 동시에 작동해야 하지만 메시징은 시간과 공간의 분리를 허용한다. ex) message queue
Distributed pervasive systems
노드가 작고 이동성이 있으며 종종 더 큰 시스템에 내장되어 있는 차세대 분산 시스템은 시스템이 사용자 환경에 자연스럽게 혼합된다는 점이 특징이다.
세 가지 하위 유형
- 유비쿼터스 컴퓨팅 시스템: 지속적으로 존재하는, 즉 시스템과 사용자 간의 지속적인 상호 작용이 있다.
- Distribution: 투명하게 네트워크 연결, 분산 및 액세스 가능
- Interaction: 사용자와 장치 간의 상호 작용은 눈에 띄지 않는다.
- Context awareness: 시스템이 상호 작용을 최적화하기 위해 사용자의 컨텍스트를 인식
- Autonomy: 기기들은 사람의 개입 없이 자율적으로 작동하며, 따라서 자기관리성이 높다
- Intelligence: 전체적으로 시스템이 광범위한 동적 동작 및 상호 작용을 처리할 수 있다
- 모바일 컴퓨팅 시스템: 널리 보급되지만, 장치가 본질적으로 모바일이다.
- 의사소통은 더 어려워질 수 있다: 안정적인 경로가 없고 연결성 보장되어 있지 않다. => Disruption-tolerant networking ex) MANET
- 센서(and actuator) 네트워크: 환경의 실제(협업적) 감지 및 작동을 강조하면서 만연하다.
- 센서가 연결된 노드는 다음과 같습니다.
- 다수(10s-1000s)
- 단순(작은 메모리/컴퓨팅/통신 용량)
- 종종 배터리 구동(또는 배터리 없음)
- 센서가 연결된 노드는 다음과 같습니다.
Sensor networks as distributed DB
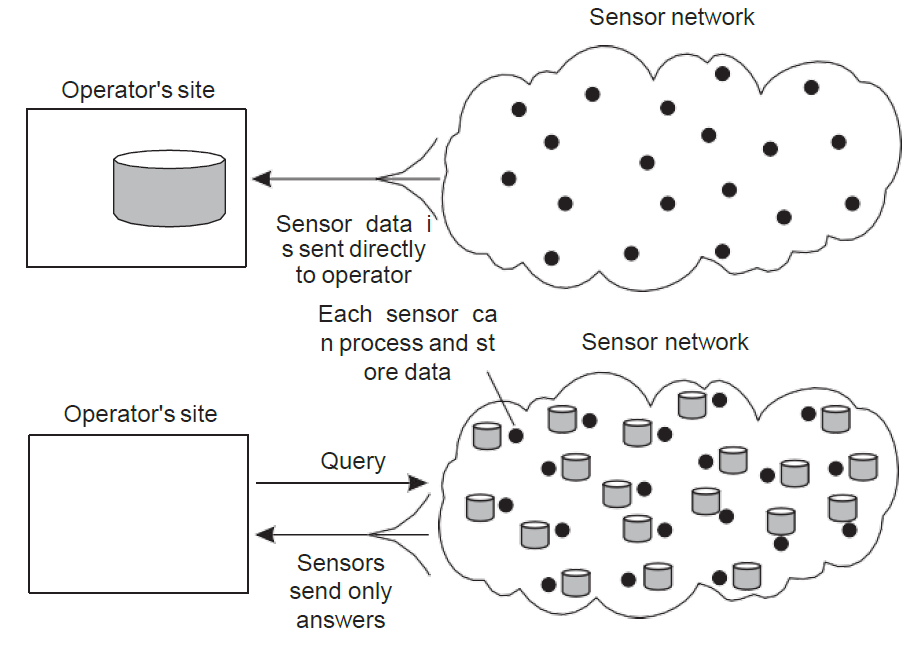
각 sensor들이 각자 DB를 구축하고 있고 data를 처리할 수 있다면 필요한 내용만을 센서가 operator에게 보냄으로써 훨씬 효율적으로 동작할 수 있다.
