[분산 컴퓨팅] Chapter 2. Architectures
in CS Review on Distributedcomputing
Chapter 2: Architectures
- Architectural styles
- Layered architectures
- Object-based and service-oriented architectures
- Publish-subscribe architectures
- System architecture
- Centralized organizations
- Decentralized organizations: peer-to-peer systems
Architectural sytles
Software architecture: 다양한 소프트웨어 구성 요소의 구성 방법 및 상호 작용 방법으로 다음 3 가지 유형이 있다.
- Centralized architectures
- Decentralized architectures
- Hybrid architectures
System architecture: 위의 소프트웨어 아키텍처가 최종적으로 인스턴스화(실체화)된 것을 말한다.
Architectural styles는 다음과 같이 정의될 수 있다.
- 잘 정의된 인터페이스를 가진(교체 가능한) 컴포넌트
- 컴포넌트가 서로 연결되는 방식
- 컴포넌트간에 교환되는 데이터
- 컴포넌트와 connector가 어떻게 시스템으로서 구성되는 가?
- Connector: 컴포넌트간의 communication, coordination, cooperation을 중재하는 메커니즘으로 RPC, messaging, streaming을 위한 기능으로 예를 들 수 있다.
분산 시스템을 위한 중요한 아키텍처 스타일로는 다음의 4 가지 유형이 있다.
- Layered architectures
- Object-based architectures
- Resource-centered architectures
- Event-based architectures
Layered architecture
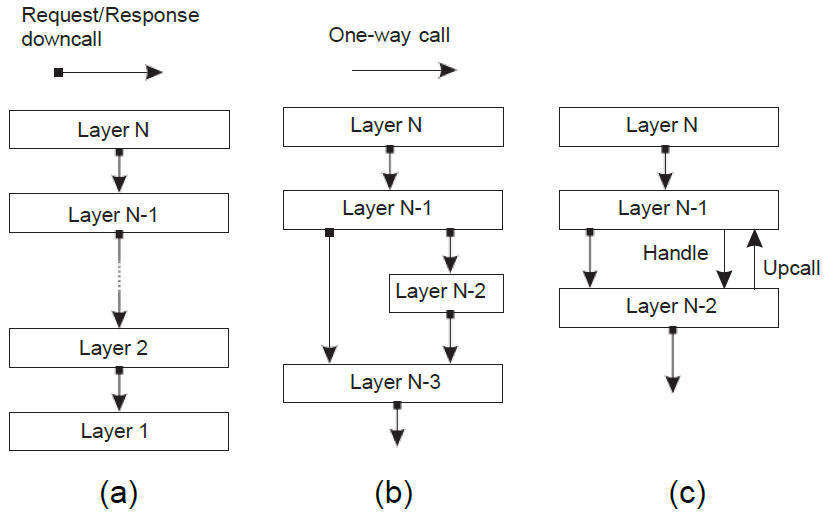
Layered architecture는 말 그대로 layer로 stack을 쌓은 구조이다. 위와 같이 3 가지 유형으로 나눌 수 있다.
a는 제일 단순한 구조로, 아래쪽 layer의 기능을 call(downcall)한다고 생각하면 된다.
b는 layer를 스킵하기도 하며 예로는 c언어의 system call을 떠올릴 수 있다. System call을 직접 호출할수도 있고, library를 통해 호출할수도 있지 않은가?
마지막으로 c는 downcall만하는 것이 아니라 그 반대인 upcall을 하는 경우가 포함된 경우이다. Upcall은 callback function또는 handler function으로 생각하면 된다.
Application을 예로 생각해볼 수 있다. 전통적인 방식으로 application을 설계하자면, 3 계층으로 설계할 수 있다.
- Application-interface layer(UI): 사용자 또는 외부 애플리케이션에 대한 인터페이스를 위한 장치 포함
- Processing layer: 어플리케이션의 함수, 로직을 담고 있다.
- Data layer: 클라이언트가 애플리케이션 컴포넌트를 통해 조작하려는 데이터가 포함(저장, 변경, 조회 등)
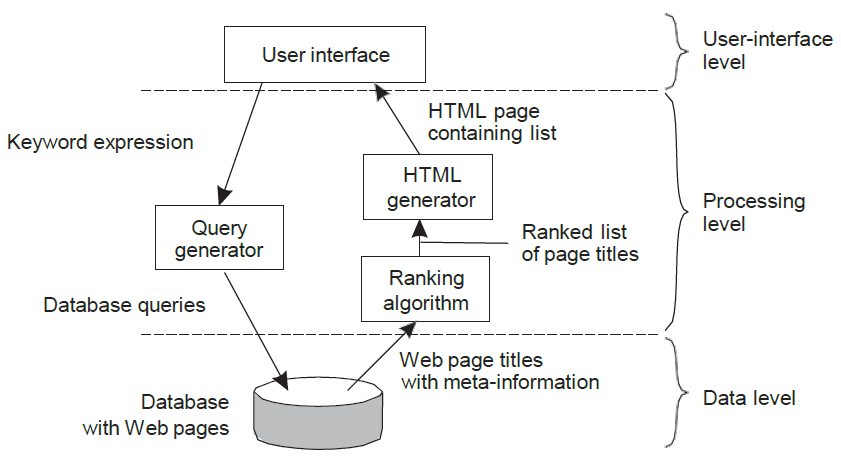
또 다른 예시로는 구글, 네이버의 서치 엔진을 떠올려 볼 수 있다. 사용자가 원하는 것을 입력하면 그 문장을 쿼리로 바꾸어서 DB에 요청한다. DB는 원하는 자료를 돌려주고 프로세싱 레이어에서 그 자료를 랭킹 알고리즘같은 알고리즘에 따라 순위를 매기고 HTML로 변환하여 유저에게 보여준다.
Object-based architecture
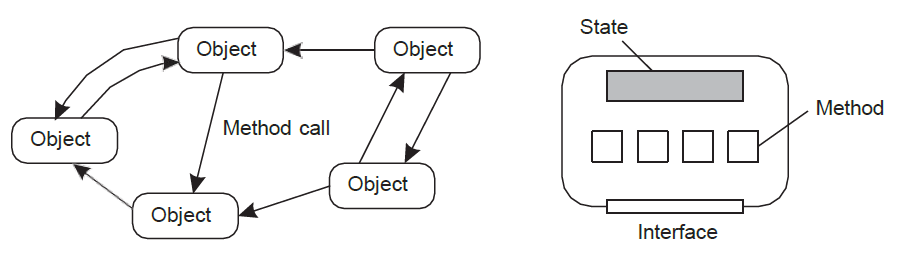
Object-based architecture에서 컴포넌트는 프로시저 호출을 통해 서로 연결되는 객체이다. 객체는 서로 다른 시스템에 배치될 수 있고 호출(method call)은 네트워크를 통해 실행될 수 있습니다. Object는 하나의 functionality로 구현되어 service를 제공한다고 생각하면 된다.
객체는 내부 구현을 드러내지 않고 데이터를 캡슐화하고 해당 데이터에 대한 method를 제공한다.
Resource-based architecture
REST(Representational State Transfer)ful architecture라고도 한다. 분산 시스템을 리소스의 집합으로 보며, 각각 컴포넌트에 의해 관리된다. 리소스들은 어플리케이션에 의해 추가(POST), 제거(DELETE), 조회(GET), 변경(PUT)될 수 있다.
리소스들은 고유한 이름 체계를 갖는데 이를 uri라고 한다. 모든 서비스들은 같은 인터페이스를 제공하고 주고 받는 메시지는 스스로 모든 정보를 담고 있다. 서비스에서 operation을 실행하면 그 컴포넌트는 caller의 모든 것을 기억하지 않는다. 이를 stateless execution이라고 한다.
아마존의 simple storage serice와 비교해볼 수 있다. Object(e.g. files, resources)들은 bucket(e.g. directories)에 위치하고 버켓들은 버켓안에 위치할 수 없다. 다음과 같은 identifier를 갖는다.
ex) http://BucketName.s3.amazonaws.com/ObjectName
모든 operation들은 HTTP request를 전송하여 수행된다.
SOAP의 경우 Bucket 및 object를 생성할 때는 POST와 URI가 필요하며, Object들을 나열할 때에는 bucket name에 GET, object를 조회할 때에는 해당 full URI에 GET을 한다.
RESTful한 approach를 사람들이 선호하는 이유는 단순해서이다.
SOAP vs. RESTful

코드만 봐도 뭐가 더 간단한지 눈에 선하지 않은가? 하지만 단순한만큼 파라미터에 많은 정보를 요구한다. URI가 복잡하다는 뜻이다!!
Event-based architecture
Publish-subscribe architecture라고도 한다. Temporal, referential coupling에 따라 아키텍처들을 구분해볼 수 있다.
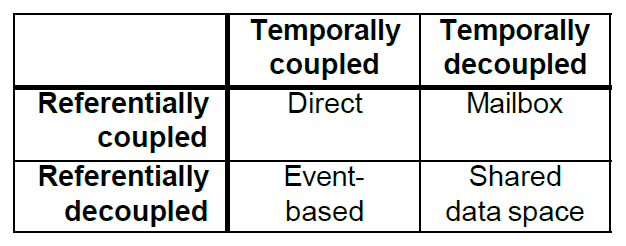
Temporal이라함은, 두 컴포넌트가 동시에 수행되는 가를 말하는 것이고 referential은 각 컴포넌트가 명시적으로 지명했는 가를 따지는 것이다. Mailbox를 예로 들면 굳이 두 컴포넌트가 동시에 작동할 필요하는 없다. 하지만, 누구에게 메일을 보낼 지는 명확해야 한다.
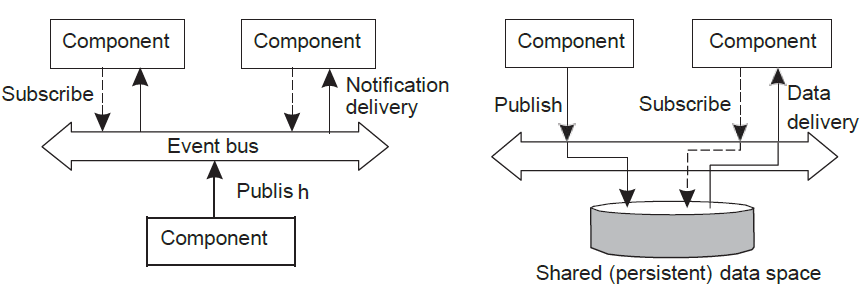
Event-based는 어떤 컴포넌트가 event bus에 어떤 event가 관심있다고 등록(subscribe)하는 것이다. 어떤 컴포넌트가 해당 event를 publish(broadcast)하면 그 순간 event bus가 해당 등록, 구독한 컴포넌트에게 notification을 날려주는 것이다. AWS의 카프카를 예로 들 수 있다.
Shared data space의 경우, 컴포넌트가 publish하면 그 정보는 shared data space에 저장되고 다른 컴포넌트가 join해서 해당 데이터를 가져가는 것이다. Linda라는 tuple space를 예로 들 수 있다.
System Architecture
Centralized system architecture
기본적인 centralized system architecture로는 Client-Server Model을 꼽을 수 있다. 서비스를 제공하는 server가 있고, 그를 사용하는 client가 있다. 이들은 다른 머신에 존재할 수 있으며, client는 server가 제공하는 request/reply 모델을 따른다.
multi-tiered로 존재할 수도 있다. 몇 부분으로 나누어지는 가를 따지는 것이다.
- Single-tiered
- Two-tiered
- Three-tiered
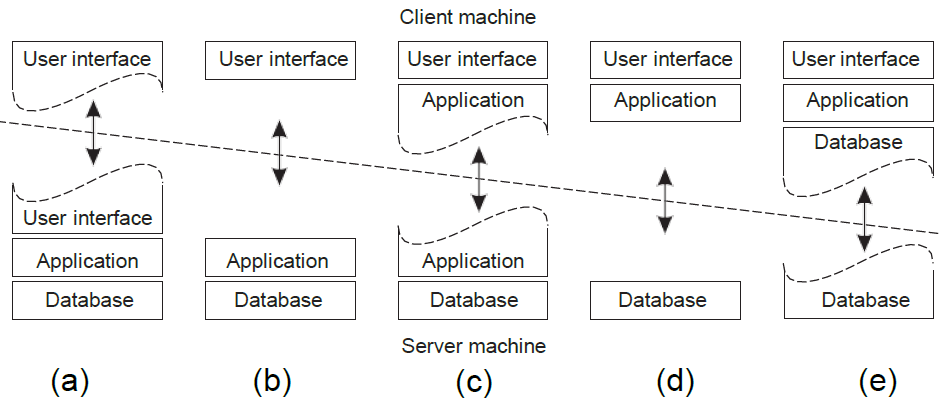
e로 갈수록 client단에서 하는 것이 많으므로 fat하다고 한다. 통상적으로 d와 e를 fat client, a,b,c를 thin client라고 한다.
a의 예시로는, application layering 그림에서 html file을 생성하는 것을 예로 들 수 있다.
b의 예시로는 FTP server를 들 수 있다.
c의 예시로는 1강에서 봤던 email form checker를 들 수 있다.
d의 예시로는 재고 관리 프로그램을 들 수 있다.
e의 예시로는 웹 브라우저 캐싱, 뱅킹 서비스 등을 들 수 있다.
Three-tiered architecture는 서버가 동시에 클라이언트의 역할을 할 때도 있는 것을 말한다.
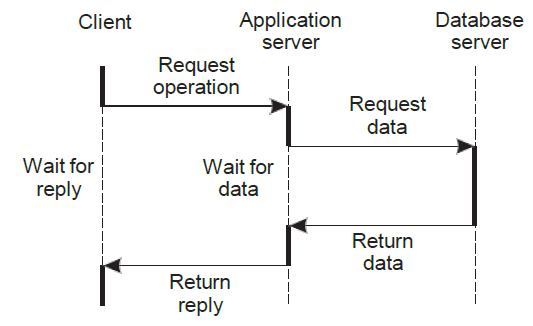
위에서 가운데 application server는 client와 통신할 때에는 server의 역할을, DB server와 통신할 때에는 client의 역할을 하고 있음을 알 수 있다.
Decentralized system architecture: peer-to-peer system
P2P 시스템을 설명하기 앞서 vertical distribution과 horizontal distribution을 알 필요가 있다. 전자는, 분산 어플리케이션을 3 개의 계층으로 나누어 각 계층의 컴포넌트를 서로 다른 서버에서 실행하는 것을 말하고, 후자의 경우 클라이언트 또는 서버는 물리적으로, 논리적으로 동등한 부분으로 분할될 수 있지만 각 부분은 전체 데이터 집합의 자체 공유로 작동하는 것을 말한다.
반면, P2P는 프로세스가 모두 동등하다. 모든 프로세스는 client인 동시에 서버처럼 동작한다. servant라고도 한다.
P2P 네트워크의 장점으로는 4가지를 꼽을 수 있다.
- 자원의 효율적인 사용
- Scalability
- Reliability
- 관리의 용이성
P2P protocol을 central indexing server와 overlay network(토폴로지)의 유무로 분류해볼 수 있다. 
Central indexing server는 centralized 여부를 결정하고 토폴로지의 유무는 structured 여부를 결정한다.
Structured P2P는 hypercube, Chord, Pastry, CAN 등이 있다. Hash function을 사용한다는 공통점이 있다.
Unstructured P2P는 overlay network가 정해지지 않고 random graph를 갖는다.
- Super-peer networks(super peer-weak peer)
- Edge-server architecture
- content server끼리는 P2P, ISP와 종단끼리는 client-server관계
1. Napster
최초의 p2p file sharing application, 저작권 이슈로 탄생 2년만에 망했다.
Napster의 작동 방식은 다음과 같다.
- 누군가 공유하고자 하는 file을 중앙 인덱싱 서버에 publish한다.
- 인덱싱 서버는 publish한 노드의 ip를 저장한다.
- 이제 다른 노드가 그 file을 찾고자 한다면 인덱싱 서버에 묻고, 있다면 해당 파일을 갖고 있는 노드의 ip를 반환해준다.
- 이제 그 ip를 가지고 서로 통신하여 file을 얻어낸다.
- 인덱싱 서버에 의존하므로 centralized이지만, fetch하는 과정은 p2p이므로 p2p 시스템이다.
장단점은 다음과 같다.
- 간단하고 search cost가 O(1)이다.
- Controllable하다. 인덱싱 서버만 꺼버리면 전체 시스템이 꺼진다.
단점일지도..? - 하지만 서버는 노드의 수만큼의 상태를 유지해야 하고 서버가 모든 요청을 처리하며 single point of failure가 존재한다.
2. Gnutella
그누텔라? 누텔라라고도 하는 이 녀석은 완전히 분산된 p2p file sharing system이다. 그누텔라 개발자들이 누텔라를 그렇게 많이 먹어서 이름이 그렇다는 썰이 있다…
인덱싱 서버가 없어서 해당 파일을 찾으려면 flooding을 통한 방식 밖에 없다. 완전히 분산되어있고 search cost 또한 분산된다는 장점이 있지만 search cost는 O(N: # of nodes)이고 search time은 예측하기 어렵다는 단점이 있다. Flooding 방식을 택하다 보니 너무 많은 트래픽이 발생하기 때문이다. 이를 방지하기 위해 random walk로 neighbor 중 하나에만 forwarding을 하는 방식도 있다. 또한 node가 항상 존재하는 것이 아니라 들락날락하는 존재라 네트워크가 매우 불안정하다.
3. KaZaA
이 시스템은 supernode를 기용하여 앞선 냅스터와 누텔라의 장점만을 취하려고 노력했다. 슈퍼노드는 로컬 노드들을 가지면서 그들과의 관계는 냅스터에서 인덱싱 서버와 노드와의 관계와 동일하다. 반면 슈퍼노드끼리는 누텔라 때처럼 완전한 p2p와 같다.
client가 파일을 찾는다면 우선 상위의 슈퍼노드에게 물어보고 없다면 슈퍼노드가 다른 슈퍼노드들에게서 찾는 방식이다.
4. DHT protocol: Distributed Hash Table
여지껏 위의 방식들은 centralized라면 directory size가 O(n), # of hops가 O(1)이고, flooded queries라면 directory size가 O(1), # of hops가 O(n)인 것을 볼 수 있었다. DHT는 둘 다 O(logn)에 처리하기 위한 방법이다.
기본적인 idea는 어떤 hash function이 있어서 object와 node 모두 하나의 hash space에 매핑하는 것이다. Hash function이라는 토폴로지가 있어서 노드들이건 오브젝트들이건 항상 정해진 위치를 갖는다.
data object는 항상 자기보다 크고 제일 가까운 노드에 저장된다. 그렇게 인터넷 전역에 퍼져서 데이터가 관리되는 것이다. 어떻게 찾을 수 있을까?
각 노드들은 successor node를 알고 있어서 연쇄적으로 request해서 찾는 방법이 있다. 이는 O(n)으로 우리가 원하는 방식이 아니다. O(logn)에 찾기 위해 finger table이라는 별도의 테이블을 만들어서 사용한다. finger table에는 2^(i-1)만큼 떨어진 곳들의 노드들을 저장한다.
ex_1) Chord Protocol
- Hash function으로 SHA-1을 사용했다.
- Ring 형태로 토폴로지가 존재한다.
- IP를 해시 함수에 넣어 얻은 결과값을 위치로 사용했다.
- Finger table은 총 m개의 엔트리로 이루어진다.
- i번째 엔트리 포인트는 n+2^(i-1)의 successor이다.
- k라는 object를 원한다면 finger table을 참조하여 범위 안에 있다면 바로 찾아가고 그렇지 않다면 제일 멀리 건너뛰어서 찾는다.
- 2의 제곱으로 움직이기에 이분 탐색처럼 작용하여 O(log n)을 달성할 수 있게 된다.
Hybrid system architecture: The BitTorrent case
비트토렌트는 매우 익숙한 프로그램이다. 2001년에 release되었고 게임 이론에 기반하여 free-rider 문제를 개선(incentive mechanism)했다. DHT와 달리 강력한 보증(DHT에서는 파일이 반드시 존재한다는 보장이 있음)이 없으며 실무에서 또한 잘 작동한다.
토폴로지는 random하게 결정되므로 Unstructured network에 해당한다.
Swarming Protocol
파일들은 아주 작은 조각들(=chunks)로 나누어진다. 그 조각들은 네트워크를 통해 전파되고 peer가 피어를 획득하면 다른 peer와 교환할 수 있게된다. 이렇게 peer끼리 piece를 서로 제공하는 것이 위에서 말한 incentive가 된다. 피어는 조각들을 모아서 마지막에 전체 파일을 어셈블하게 된다.
chunk는 보통 256kb이고 각 peer는 bit map을 갖고 있어서 어떤 chunk가 있고 없는 지를 확인할 수 있다. 결과적으로 neighbor peer들에게 자기가 무엇을 갖고 있고 무엇이 필요한 지를 알려준다.
Basic Components
- Web server: 콘텐츠 검색(= 파일 검색)은 웹 서버를 사용하여 비트토렌트 외부에서 처리
- .torrent file: 필요한 메타 정보를 저장하는 정적 파일
- 이름, 크기, 체크섬, 트래커 노드의 IP 주소 및 포트
- 각 chunk가 체크섬 값으로 해시된다
- Peer가 나중에 다른 peer에서 chunk를 가져올 때 체크섬을 비교하여 신뢰성을 확인할 수 있다
- Tracker: peer 추적, 활성화된 peer의 random list(=neighbor list) 가지고 있음
- Peers: downloader(leecher)와 seeder로 나눠짐
- downloader: 파일의 일부분만 갖고 있는 peer
- seeder: 완전한 파일을 갖고 있는 peer
Rarest First
- 더 희귀한 piece들은 다운로드에 우선권이 주어지며, 첫 번째 후보가 된다.
- 가장 일반적인 조각은 제일 끝으로 연기된다.
- 이 정책은 다양한 조각이 시더에서 다운로드되도록 보장하여 더 빠른 청크 전파를 가능하게 한다.
Peer Selection
- tit-for-tat 전략(반복게임에서 유저가 이전 게임에서 상대가 한 행동을 그대로 따라한다, 협조적이면 협조적으로 비협조적이면 비협조적으로)을 사용한다.
- 청크를 교환할 “친구”를 4-5명 유지한다
- 만약 친구가 만족스런 속도로 chunk를 주고 있지 않는다면 제거한다.(=choking)
- 정기적으로 무작위로 새 친구를 선택한다.(=optimistic unchoking, 잘해주면 잘해주는가?)
- 만약 친구가 없다면, 무작위로 몇 명의 새로운 친구들을 선택한다.(=anti-snubbing)
만약 주고받는 것이 video라면? P2P video
Rarest first가 아닌 재생 시점에서 가까운 것을 가져와야 한다. chunk selection이나 peer selection 모두 재생 시점에서 가까운 것을 가져와야 하므로 달라진다.
Hybrid인 이유?
client가 우선 web server에 파일을 look up한다. 이는 client-server 구조이고 web server, file server, tracker를 거쳐서 얻은 neighbor node들과의 통신은 p2p이므로 decentralized이다. 이렇게 섞여있다.
Some essential details
- Neighbor set: B가 A의 neighbor set에 속한다면 A도 B의 neighbor set에 속한다. 트래커에 의해 주기적으로 업데이트 된다
- Potential set: Neighbor B가 A가 원하는 block(=piece를 또 나눈 것)을 갖고 있다면 B는 A의 potential set이다.
- 서로가 potential set에 속하면 교환한다.
BitTorrent phases
- Bootstrap phase: A가 optimistic unchoking을 통해 첫번째 piece 얻기
- Trading phase: PA > 0으로 항상 A가 trade할 peer가 존재한다.
- Last download phase: PA=0으로 A는 새로운 peer에 의존하여 missing piece들을 찾는다. 이 때 neighbor set은 트래커를 통해서만 변경이 된다.
