[쿠버네티스] Chapter 2. Understanding Containers
in CS Review on Kubernetes
Containers
시스템이 소수의 애플리케이션으로 구성된 경우 각 애플리케이션에 전용 vm을 할당하고 각 애플리케이션을 자체 os에서 실행하는 것이 좋다. 그러나 마이크로서비스의 크기가 점점 작아지고 그 수가 증가하기 시작하면서 각 application마다 vm을 제공하기 어려워졌다. 결국, 하드웨어 비용과 리소스 낭비 문제로 귀결된다.
낭비 문제뿐만이 아니라, 관리 비용도 증가한다. 많은 수의 vm을 실행하면 requirements가 더 늘어나고 더 복잡한 자동화 시스템이 요구된다. 결과적으로 vm의 대안으로 컨테이너가 탄생했다.
Container vs. VM
이제 대부분의 DevOps팀은 VM으로 개별 마이크로 서비스의 환경을 격리하는 대신 컨테이너를 사용하는 것을 선호한다. 여러 서비스를 동일한 호스트 컴퓨터에서 실행하면서도 서로 격리시킬 수 있는데, 이는 VM과 비슷하지만(격리 측면) 오버헤드가 훨씬 적다.
각각 여러 시스템 프로세스로 별도의 os를 실행하는 VM과 달리 컨테이너에서 실행되는 프로세스는 기존 호스트 os 내에서 실행된다. os가 하나만 있기 때문에 중복된 시스템 프로세스가 없다. 모든 애플리케이션 프로세스들이 동일한 os 위에서 실행되지만 환경은 별도의 VM에서 실행되는 것처럼 분리된다. 컨테이너의 프로세스에서는 이러한 분리로 인해 컴퓨터에 다른 프로세스가 없는 것처럼 보이게 된다. 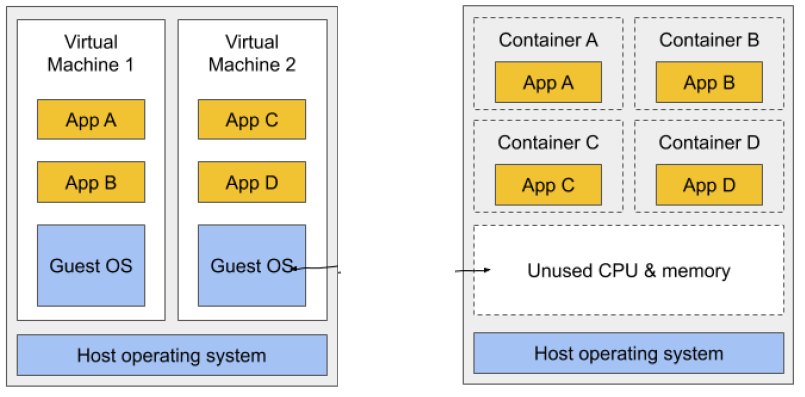
컨테이너는 오버헤드를 유발하지 않으므로 각 애플리케이션에 대해 별도의 컨테이너를 만들 수 있고 실제로 동일한 컨테이너에서 여러 개의 애플리케이션을 실행해서는 안 된다. 컨테이너의 프로세스를 관리하는 것이 훨씬 더 어려워지기 때문이다. 게다가, 쿠버네티스 자체를 포함하여 컨테이너를 다루는 모든 기존 소프트웨어는 컨테이너에 하나의 애플리케이션만 있다는 전제 하에 설계되었다.
런타임 오버헤드가 낮을 뿐만 아니라, 응용 프로그램 프로세스 자체만 시작하면 되기 때문에 컨테이너는 응용 프로그램을 더 빨리 시작할 수 있다. VM과 달리 시스템 프로세스를 먼저 시작할 필요가 없습니다.
자원 사용에 있어서는 컨테이너가 더 낫다는 데에 이견이 없겠지만, 단점도 있다. VM이 container에 비해 격리된 정도가 훨씬 높다. VM에서 applciation의 os가 죽으면 그 application만 영향을 받지만 컨테이너의 경우 다른 컨테이너들도 영향을 받을 수 있다.
또한 보안 관점에서도 컨테이너가 위험하다. 커널에 버그가 있는 경우, 한 컨테이너에 있는 애플리케이션이 다른 컨테이너에 있는 애플리케이션의 메모리를 읽기 위해 버그를 사용할 수 있다. 애플리케이션이 서로 다른 VM에서 실행되어 하드웨어만 공유하는 경우 이러한 공격이 발생할 확률은 훨씬 낮다.
또한 각 VM은 자체 메모리 청크를 사용하는 반면, 컨테이너는 메모리 공간을 공유한다. 따라서 컨테이너에서 사용할 수 있는 메모리 양을 제한하지 않으면 다른 컨테이너의 메모리가 부족해지거나 데이터가 디스크로 스왑 아웃될 수 있다.
Docker container platform
도커(Docker)는 응용 프로그램을 패키징, 배포, 실행을 위한 플랫폼이다.
- Images: 컨테이너 이미지는 응용 프로그램을 패키징하는 것으로 메타 데이터(경로, 이미지 정보 등)들이 포함된다.
- Registries: 다른 사용자와 컴퓨터 간에 이미지를 교환할 수 있는 컨테이너 이미지의 리포지토리
- Containers: 컨테이너 이미지에서 컨테이너가 인스턴스화된다.
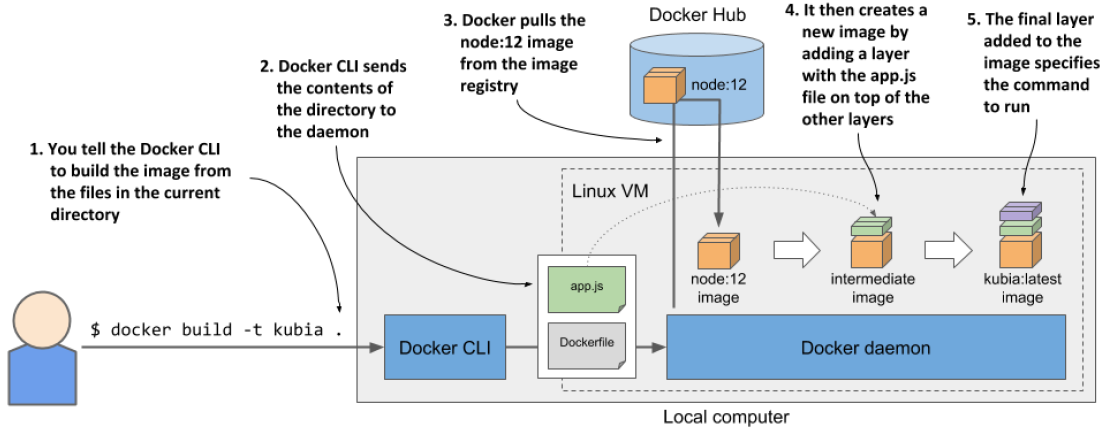
위 세 가지가 어떻게 관련이 있으며 container image를 build하는 지 알아보자.
- 개발자는 먼저 도커를 통해 이미지를 빌드하고 도커는 local에 저장한다.,
- 개발자는 도커를 통해 이미지를 레지스트리에 푸시한다.
- 이제 레지스트리에 액세스할 수 있는 모든 사용자가 이미지를 사용할 수 있게 된다.
- Docker는 이미지를 기반으로 격리된 컨테이너를 만들고 이미지에 지정된 실행 파일을 호출함으로써 사용자가 쓸 수 있게 된다.
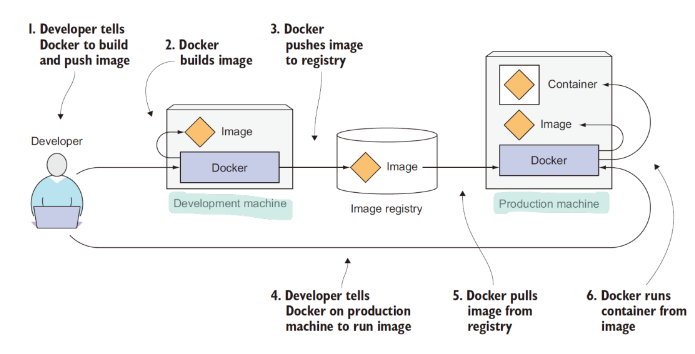
Image layers
VM에 설치된 운영 체제에 필요한 전체 파일 시스템의 큰 덩어리인 가상 시스템 이미지와 달리 컨테이너 이미지는 일반적으로 훨씬 더 작은 계층으로 구성된다. 이러한 계층은 여러 이미지에서 공유 및 재사용할 수 있다.
레이어는 이미지 배포를 매우 효율적으로 만들지만 이미지의 저장 공간을 줄이는 데에도 도움이 된다. 도커는 각 레이어를 한 번만 저장하기 때문이다.
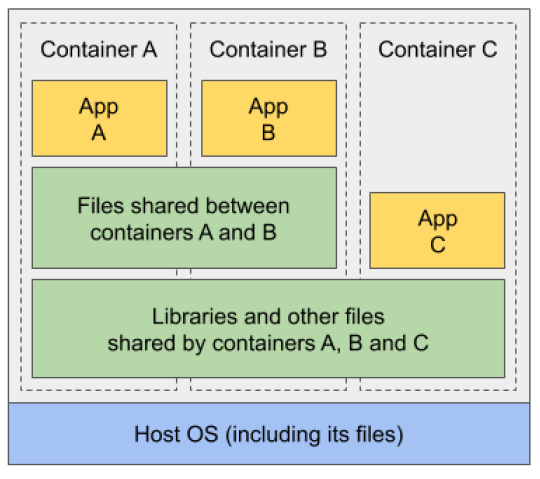
위 그림에서처럼 세 컨테이너가 모두 동일한 파일에 액세스할 수 있다면, 어떻게 서로 완전히 격리될 수 있을까? 애플리케이션 A가 공유 계층에 저장된 파일에 대한 변경 사항을 애플리케이션 B에서는 보이지 않을까? 답은 “그렇지 않다”이다.
파일 시스템은 CoW(Copy-on-Write) 메커니즘에 의해 격리된다. 컨테이너의 파일 시스템은 컨테이너 이미지의 읽기 전용 레이어와 상단에 적층된 추가 읽기/쓰기 레이어로 구성된다. 쉽게 말하면, 변경할 일이 있으면 복사해서 변경하고 포인터를 옮겨준다는 뜻이다.
파일을 삭제하면 읽기/쓰기 계층에서만 삭제된 것으로 표시되지만 아래 계층 중 하나 이상에 여전히 존재하므로 파일을 삭제해도 이미지 크기가 줄어들지 않는다.
이론적으로 도커 기반 컨테이너 이미지는 도커를 실행하는 모든 리눅스 컴퓨터에서 실행될 수 있지만 컨테이너가 자체 커널을 가지고 있지 않기 때문에 한 가지 작은 주의사항이 존재한다. 컨테이너형 응용 프로그램이 특정 커널 버전을 필요로 하는 경우 모든 컴퓨터에서 작동하지 않을 수 있다. 컴퓨터가 다른 버전의 Linux 커널을 실행 중이거나 필요한 커널 모듈을 로드하지 않으면 앱을 실행할 수 없다.
Docker를 사용할 수 있다고 해서 x86 CPU 아키텍처용으로 컴파일된 응용 프로그램을 컨테이너에 넣고 ARM 기반 컴퓨터에서 실행할 것으로 기대할 수는 없다. 이를 위해서는 x86 아키텍처를 에뮬레이트할 VM이 필요하게 된다.
Installing and Running Docker
Building a New Container Image
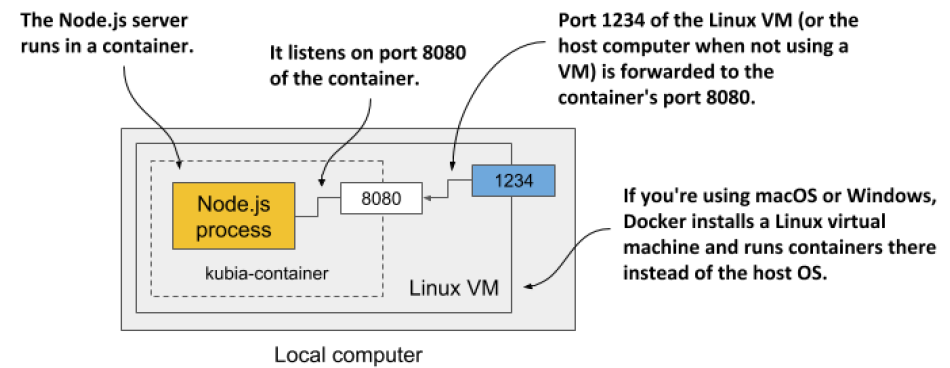
Running containers
Container Technology
Linux namespaces
각 프로세스가 시스템에 대한 고유한 view를 갖게 함, 컨테이너에서 실행되는 프로세스는 별도의 가상 머신에서 실행되는 것처럼 시스템의 일부 파일, 프로세스 및 네트워크 인터페이스만 볼 수 있고 다른 시스템 호스트 이름도 볼 수 있다.
처음에 파일 시스템, 프로세스 ID, 사용자 ID, 네트워크 인터페이스 등 리눅스 OS에서 사용할 수 있는 모든 시스템 리소스는 모든 프로세스가 보고 사용하는 동일한 버킷에 있다.
그러나 커널을 사용하면 네임스페이스라고 하는 추가 버킷을 만들고 리소스를 이 버킷으로 이동하여 더 작은 세트로 구성할 수 있다. 이렇게 하면 각 집합을 하나의 프로세스 또는 프로세스 그룹에만 표시할 수 있다.
- 마운트 네임스페이스(mnt): 마운트 지점(파일 시스템)을 분리
- 프로세스 ID 네임스페이스(pid): 프로세스 ID를 분리
- 네트워크 네임스페이스(net): 네트워크 장치, 스택, 포트 등을 분리
- 프로세스 간 통신 네임스페이스(ipc): 프로세스 간의 통신을 격리(메시지 대기열, 공유 메모리 등).
- UNIX 시간 공유 시스템(UTS) 네임스페이스: 시스템 호스트 이름과 NIS(네트워크 정보 서비스) 도메인 이름을 분리
- 사용자 ID 네임스페이스(사용자): 사용자 및 그룹 ID를 분리
- Cgroup 네임스페이스: Control Groups 루트 디렉터리를 분리
결과적으로 네임스페이스를 사용하면 각 프로세스는 고유한 환경을 갖게 된다. 또한 원하는 유형의 네임스페이스를 공유하여 사용할 수도 있다.
요약하면, 프로세스는 일부 리소스를 공유하지만 다른 리소스는 공유하지 않을 수 있습니다. 프로세스에는 각 유형에 대해 연결된 네임스페이스가 있기 때문이다.
Isolated Process Tree
컨테이너의 프로세스 ID가 호스트의 프로세스 ID와 다르다. 컨테이너는 자체 프로세스 ID 네임스페이스를 사용하기 때문에 자체 ID 번호 시퀀스를 가진 자체 프로세스 트리가 있다. 즉, 컨테이너 자체의 pid와 호스트 os에서의 pid가 달라지게 되어 각 프로세스에는 두 개의 id가 있게 된다. 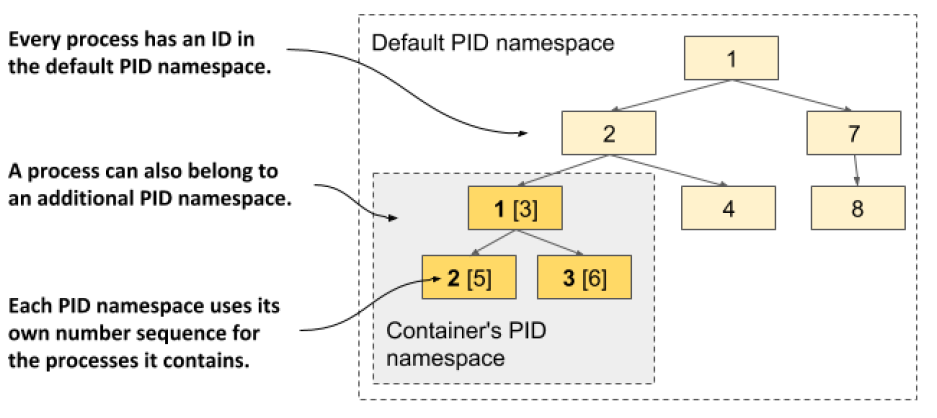
Linux Control Groups (cgroups)
Linux 네임스페이스를 사용하면 프로세스가 호스트의 일부 리소스에만 액세스할 수 있지만 각 프로세스가 사용할 수 있는 단일 리소스 양을 제한하지는 않는다.
예를 들어 네임스페이스를 사용하여 프로세스가 특정 네트워크 인터페이스에만 액세스하도록 허용할 수 있지만 프로세스가 사용하는 네트워크 대역폭을 제한할 수는 없다.
마찬가지로 네임스페이스를 사용하여 프로세스에 사용할 수 있는 CPU 시간이나 메모리를 제한할 수 없다. 한 프로세스가 모든 CPU 시간을 소비하고 중요한 시스템 프로세스가 제대로 실행되지 않도록 하려면 cgroup이 필요하다.
cgroups를 사용하는 경우 프로세스 또는 프로세스 그룹은 할당된 CPU 시간, 메모리 및 네트워크 대역폭만 사용할 수 있다. 이렇게 하면 프로세스가 다른 프로세스를 위해 예약된 리소스를 점유할 수 없습니다.
결과적으로 리눅스 네임스페이스와 C 그룹은 컨테이너의 환경을 분리하고 한 컨테이너가 다른 컨테이너를 starving하지 않게 만든다.
Capabilities
그러나 이러한 컨테이너의 프로세스들은 동일한 시스템 커널을 사용하기 때문에 정말로 고립되었다고 할 수 없다. 악성 컨테이너는 이웃에게 영향을 미치는 악의적인 시스템 호출을 할 수 있다.
언뜻 보기에 컨테이너들 중 하나에 있는 악성 프로그램은 다른 컨테이너에 손상을 입힐 수 없지만 만약 악성 프로그램이 모든 컨테이너가 공유하는 시스템 시계를 수정한다면 어떻게 될까?
애플리케이션에 따라 시간을 변경하는 것은 큰 문제가 되지 않을 수 있지만 프로그램이 커널에 시스템 호출을 할 수 있도록 허용하면 사실상 무엇이든 할 수 있다. sys-calls는 커널 메모리를 수정하고 커널 모듈을 추가하거나 제거할 수 있게 하며, 일반 컨테이너가 해서는 안 되는 많은 다른 것들을 가능하게 한다.
결과적으로, 사용자가 신뢰하고 실제로 추가 권한이 필요한 프로그램만 권한 있는 컨테이너에서 실행되어야 한다.
- Principle of least privilege
- 네임스페이스/C 그룹을 사용하더라도 프로세스는 실제로 분리되지 않는다. = 동일한 시스템 커널을 사용한다.
- 커널에 대한 일부 sys-call은 안전하고 모든 프로세스에서 사용할 수 있지만, 다른 것들은 높은 권한을 가진 프로세스만을 위해 예약된다.
- 컨테이너에는 모든 권한의 하위 집합이 부여된다.
- 각 기능은 컨테이너의 프로세스에서 사용할 수 있는 권한 집합을 나타낸다.
- 리눅스 커널은 권한을 기능이라고 하는 단위로 나눈다.
- CAP_NET_ADM인
- CAP_NET_BIND_SERVICE
- CAP_SYS_TIME
필요한 previlege만 사용하게 끔하는 것이 capabilities이다.
Docker compose vs. Swarm vs. K8s
- Docker: 컨테이너에 사용되는 핵심 기술이며 단일 컨테이너형 애플리케이션을 배포할 수 있다
- Docker Compose: 동일한 호스트에서 여러 Docker 컨테이너를 구성하고 시작하는 데 사용되므로 각 컨테이너를 별도로 시작할 필요가 없다.
- Docker swarm: 여러 호스트(Cluster)에서 컨테이너를 실행하고 연결할 수 있는 컨테이너 오케스트레이션 도구입니다.
- K8s: 쿠버네티스는 도커 스웜과 유사하지만 자동화가 쉽고 더 높은 수요를 처리할 수 있다. 규모가 더 크고 일반적으로 더 어렵다.
