[인공지능] AI - CS231n 7강 Training Neural Networks, Part 2
cs231n 7강 youtube 강의 링크
cs231n 공개 강의자료
cs231n 과제 링크
CS231n 7강 - Training Neural Networks, Part 2
Keywords
- Condition number
- local minima / saddle point
- SGD + Momentum
- Nesterov Momentum
- AdaGrad
- RMSProp
- Adam(Momentum+AdaGrad+RMSProp+Bias Correction)
- Quasi-Newton methods(BGFS)
- Model Ensembles
- Dropout / Inverted Dropout
- Data Augmentation(Horizontal Flips / Random crops and scales / Color jitter… )
- DropConnect / Fractional Max Pooling / Stochastic Depth
- Transfer Learning
지난 시간에 활성화 함수와 가중치 초기화, 데이터 전처리, BN, 하이퍼파라미터 탐색하는 방법 등에 대해 배웠다. 여전히 신경망을 학습시키기 위해 알아야 하는 것들이 더 있다. 바로 최적화이다. 최적화하는 방법과 그를 도와주는 regularization, transfer learning에 대해 살펴볼 것이다.
1. Fancier Optimization
예전에도 최적화와 관련하여 배운 적이 있다. 궁금하면 클릭!! 그때는 loss를 줄이기 위한 방법으로 SGD에 대해 배웠었다. 이번에도 같은 틀이지만 다른 방법들을 배워보려 한다.
SGD에는 문제점이 있다. 1) 손실 함수의 개형에 따라, 또 2) local minima나 saddle point에 따라, 3) mini-batch 사용에 따라 문제가 발생한다.
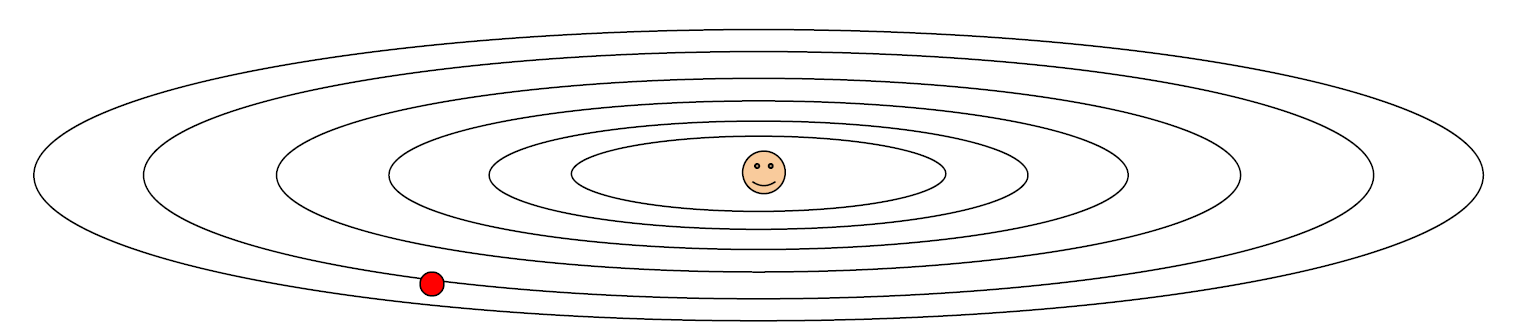
위와 같이 W1, W2가 2차원의 벡터 공간에서 빨간점이 최적을 향해 탐색할 때의 경우를 보자. 수직으로는 loss가 가파르게 변하고 수평으로는 loss가 아주 천천히 변한다.
즉, 수직 방향으로만 민감하기 때문에 동일하게 이동을 못하는 것이다. 이로 인해 loss가 지그재그로 최적을 향해 가는 것을 볼 수 있다. (taco shell, condition number, singular value of the hessian matrix에 대해 서술~~)
이 문제는 고차원으로 가면 더 빈번하게 발생한다. 왜일까? 파라미터의 수가 많아지면 문제가 생긴다는 이야기인데, 결국 파라미터의 수가 많아짐에 따라 일반적으로 방향의 불균형이 그만큼 많이 발생하기 때문이다. 다시 말해, 방향의 sensitive한 정도가 서로 비슷해야지 최적을 찾아가는데 더 효율적이다.
local minima인 경우를 살펴보자. local minima는 다항함수의 극소점을 생각해보면 된다. 극소점은 여러 구간에 걸쳐 있지만 그 중 하나라도 valley 형태의 구간에 빠지게 되는 순간 다른 극소점을 향해 탐색이 안되는 문제가 발생한다.
이번엔 saddle point인 경우를 살펴보자. saddle point는 얼핏보면 변곡점과 비슷한 개념같지만 아니다. 다차원 벡터 공간으로 확장해서 이해해야 하는데, 어떻게 보면 극소이고 어떻게 보면 극대인 point를 말한다.
일반적인 상식으로 고등학교 수학.. 우리의 loss는 매우 고차원일 것이니 저런 valley가 많이 생겨서 local minima인 경우가 빈번할 것 같지만 실제로는 saddle point가 빈번한 문제이다. 그 이유를 간략히 설명하자면, local minima가 형성되기 위해선 어떤 지점에서 모든 축의 방향으로 오목한 형태가 형성되어야 하는데 실제로 고차원 공간에서 그렇게 형성될 확률은 0에 가깝기 때문이다. 경험적으로 아는 사실인 것 같네요..
마지막으로 mini-batch의 문제점을 살펴보자. mini-batch를 통해 gradient를 추정하기 때문에 이는 정확한 값이 아니다. 즉, gradient에 noise가 섞여서 헤맬 여지가 있는 것이다. 아무래도 정확한 값을 알고 하는 것보다는 도달하는 시간이 오래 걸릴 것이다.
아무튼 위와 같은 이유들로 최적의 업데이트를 잘 하지 못해서 학습을 멈추거나 느려진다. 이제 문제점을 알았으니 개선해보자.
SGD + Momentum

업데이트가 느려지니까 그 부분에 빠지기 전에 뭔가 힘을 더 추가할 방법이 없을까? 바로 Momentum을 이용하는 것이다. 즉, 속도 변수 vx를 두어서 gradient와 함께 계산한다. 이때, rho라는 계수가 필요한데 이는 마찰계수와 같다고 보면 된다. 주로 0.9나 0.99로 설정한다고 한다.
결과적으로, 속도가 있으니 본연의 gradient가 0이 되더라도(local minima or saddle point) 업데이트가 잘 되도록 하는 것이다.
어떻게 이러한 점이 앞서 소개한 지그재그로 최적화하는 것을 어떻게 해결할까?
Noise 문제는 어떻게 해결할까?
Nesterov Momentum
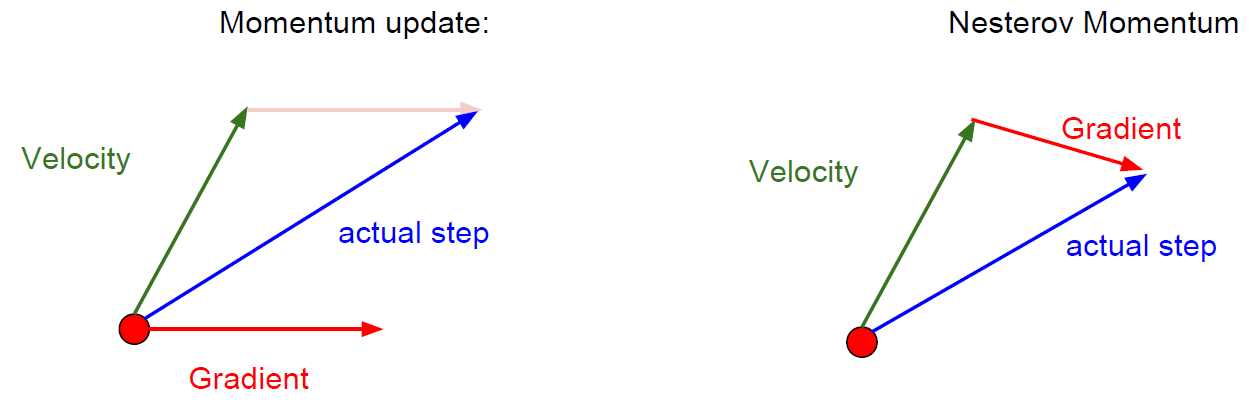
Nesterov Momentum은 SGD Momentum에서 velocity 방향이 잘못되었을 경우를 우려하여 개선된 방식이다. 그림을 보면 왼쪽의 SGD Momentum의 경우 현재 지점에서의 속도 벡터와 기울기 벡터를 사용하는 반면, Nesterov는 velocity만큼 나아간 지점에서의 gradient를 사용한다. 이를 식으로 살펴보면 아래와 같다.

또한 Nesterov Momentum은 현재와 과거의 velocity간의 에러를 보정하는데 이를 위의 그림에서 아래 박스의 두 번째 식을 보면 알 수 있다. p(Vt+1-Vt) 부분을 말하는 건데, 저 식들을 잘 조합하면 정리할 수 있다. 혹시 모를 수도 있으니 정리 과정을 아래 그림을 통해 이해하자. 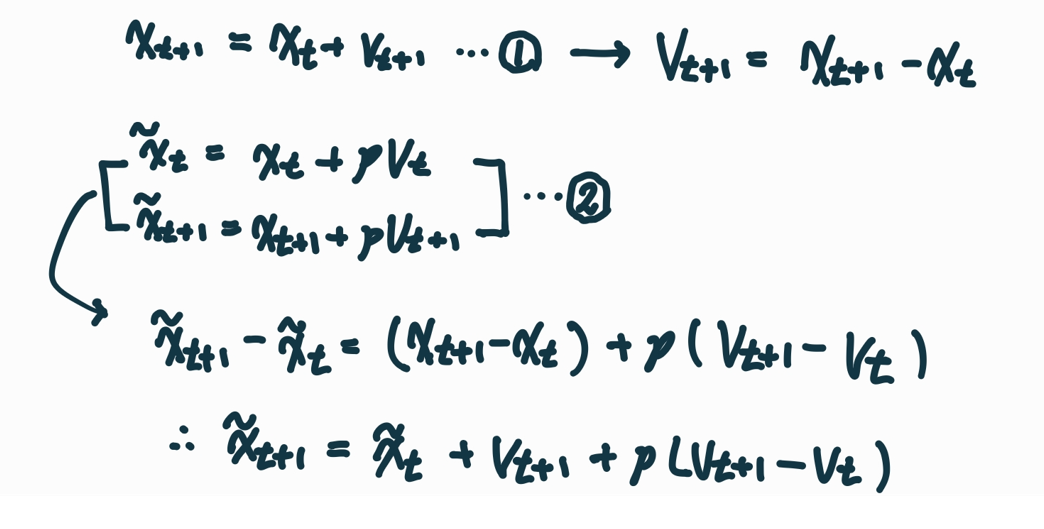
Q1. Momentum 때문에 local minima에 빠지지 않을 수 있는데, 좁고 깊은 minima를 놓치는 경우가 있어 단점도 있지 않을까?
좁고 깊은 minima는 애시당초 우리가 찾고자 하는 minima가 아니다. 왜냐면 이 minima를 이용하여 학습할 경우 overfitting이 될 수 있기 때문이다. 왜 overfitting이 되냐고? 이런 좁고 깊은 minima는 train data가 많아진다면 점점 평평해지는 부분들이기 때문이다. 그렇기 때문에 보다 평평한 minima를 찾아야 한다. 이를 통해 우리의 모델이 더 일반화를 잘해서 test 시에 좋은 결과를 내기 때문이다.
AdaGrad
 업데이트가 잘 안되는 구간에서 움직이는 또 다른 방법이다. train 시에 얻어지는 gradient를 제곱해서 더해주고 이 값으로 나누어줌으로 작은 값은 커지게
업데이트가 잘 안되는 구간에서 움직이는 또 다른 방법이다. train 시에 얻어지는 gradient를 제곱해서 더해주고 이 값으로 나누어줌으로 작은 값은 커지게당연히 작은 값으로 나누니까큰 값은 작아지게 만든다. 즉, 너무 업데이트가 느린 것은 일부러 보폭을 늘려주고 되려 너무 빠른 것은 보폭을 줄여준다.
하지만 gradient를 제곱해서 더해주는 것이 계속 누적되기 때문에 결과적으로 나눠주는 값이 커지므로 보폭이 점점 줄어든다. 이는 convex 개형에서는 효과적일 수 있으나, 그렇지 않은 경우에는 학습이 멈출 수도 있다.
RMSProp
 앞선 AdaGrad는 계속 누적이 되기 때문에 문제점이 나타났었는데 이를 약간 개선했다. 바로 decay rate를 적용하여 값이 빠르게 커져가는 것을 방지했다. decay rate로 하여금 값이 변화하는 속도를 가속하거나 감속할 수 있으며 일반적으로 0.9나 0.99를 쓰는 것으로 보아 새로운 기울기보다 과거의 값에 더 중점을 두는 것 같다.
앞선 AdaGrad는 계속 누적이 되기 때문에 문제점이 나타났었는데 이를 약간 개선했다. 바로 decay rate를 적용하여 값이 빠르게 커져가는 것을 방지했다. decay rate로 하여금 값이 변화하는 속도를 가속하거나 감속할 수 있으며 일반적으로 0.9나 0.99를 쓰는 것으로 보아 새로운 기울기보다 과거의 값에 더 중점을 두는 것 같다.
결국 AdaGrad처럼 어느 순간엔 너무 커져서 보폭이 작아지겠지만 그래도 어느정도까지는 보폭이 줄어드는 문제를 해결할 수 있다.
Adam
우리가 여태까지 배운 Momentum과 AdaGrad, RMSProp의 장점들만을 모아 만든 최적화 방식이 Adam이다.
 위 코드를 보면 first momentum과 second momentum을 사용해서 업데이트 한다. First momentum은 beta1의 계수를 둔 gradient의 합이고, second momentum은 beta2의 계수를 둔 gradient의 제곱의 합을 사용했다. 그런 점에서 First momentum은 Momentum의 특성을 보이며, second momentum은 AdaGrad, RMSProp의 특성을 보인다.
위 코드를 보면 first momentum과 second momentum을 사용해서 업데이트 한다. First momentum은 beta1의 계수를 둔 gradient의 합이고, second momentum은 beta2의 계수를 둔 gradient의 제곱의 합을 사용했다. 그런 점에서 First momentum은 Momentum의 특성을 보이며, second momentum은 AdaGrad, RMSProp의 특성을 보인다.
하지만 이렇게만 하면 문제가 있다. 초기 step에서 second momentum이 0이고 한 번의 iteration후에도 여전히 0에 가깝기 때문에 beta1과 beta2는 decay rate처럼 0.9, 0.99의 값을 갖기 때문 처음부터 매우 큰 보폭을 갖게 된다.
물론 분자인 lr*first_moment도 작은 값이라서 작은 값을 작은 값으로 나누어서 상쇄될수도 있느냐 묻는다면 그럴 수 있지만 안 그럴 수도 있다는 것이 문제이다.
Q1. 분모에 10-7을 더해주는 이유는?
분모가 0이 안되게 보상한 것이다.
이를 해결하기 위해 bias correction을 추가해준다. 현재의 step에 맞게 적절한 bias를 주입해서 step이 안정되게 만들어준다. 이것이 완전한 Adam이다.
우리가 파악한 문제점들을 개선해서 만든 것이기에 일반적으로 Adam을 많이 쓰곤한다. 하지만 여전히 Adam 또한 손실함수의 개형이 타원형이면서 축에 대해 기울어져 있다면 해결하지 못한다.
우리가 배운 SGD, SGD Momentum, AdaGrad, RMSProp, Adam 모두 1차 미분을 활용한 first-order optimization으로 learning rate를 하이퍼파라미터로 사용하고 있다.
적절한 learning rate는 어떻게 찾을까? Learning rate decay라는 방법을 써볼 수 있다. 처음에는 조금 높게 잡은 후 점차 낮춰보는 것이다. Exponential하게 decay할 수도 있고 각 time step만큼 나눠줄 수 있다. 이러한 learning rate decay는 Adam 보단 SGD Momentum에서 자주 쓰인다고 한다.
결국, loss curve를 잘 살피면서 decay가 필요한 부분이 어디인가를 잘 따져서 사용하는 것이 제일 좋다.
First-Order / Second-Order Optimization
2차 미분을 활용한 방법은 1차 미분을 활용한 방법보다 minima에 더 잘 근접한다. 수치해석시간에 좀 자세히 다뤘던 기억이 난다. 아래 그림만 봐도 왜 그런지 직관적으로 알 수 있다. 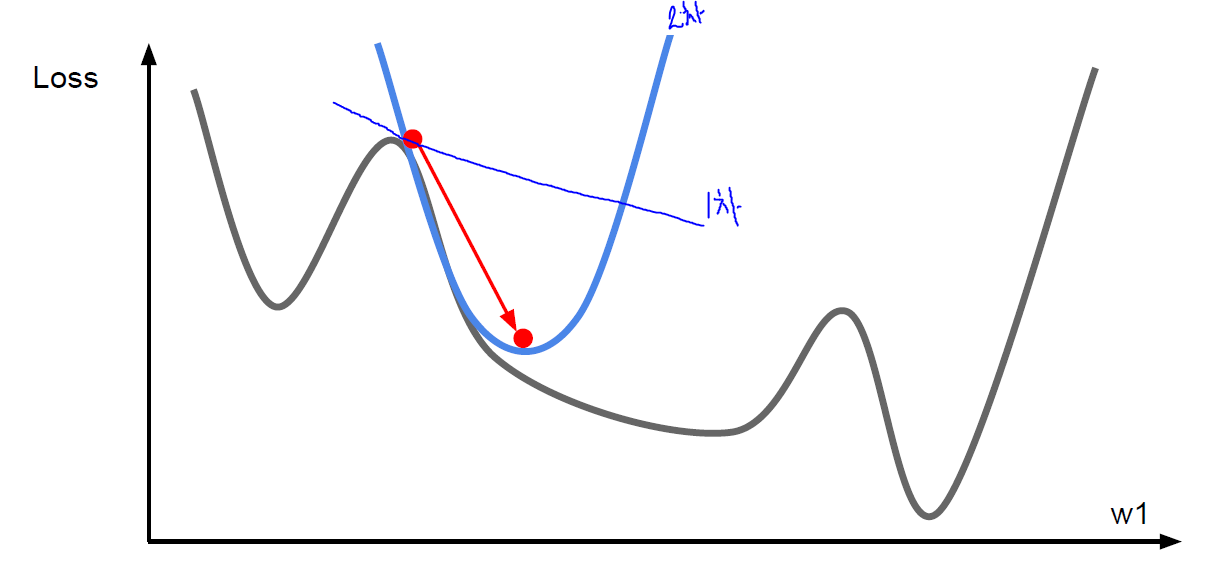
2차 미분값들로 이루어진 행렬인 Hessian matrix의 역행렬을 이용해서 실제 손실함수의 2차 근사를 얻고 그의 minima로 이동하여 빠르게 접근한다.
위 흐름 상으론 learning rate가 없지만, 실제로는 learning rate를 사용한다. minima로 곧장 이동하는게 아니라 접근해가는 것이기 때문이다.
뭐가 되었든, 딥러닝에서는 사용할 수 없는데, Hessian matrix는 NxN행렬이고 N은 네트워크의 파라미터 수인데 이를 메모리에 담을 방법이 없기 때문이다. 역행렬 계산은 연산량도 많은데 어떻게..ㅎ
그래서 실제론 quasi-newton metod를 사용한다. Hessian의 역행렬을 구하기O(n3) 보단 근사해서 low-rank로 사용한다.
2. Model Ensembles
지금까지는 모두 training error를 줄이기 위한 방법들이었으며, 손실함수를 최소화시키기 위한 역할이었다. 그러나, 우린 결국 어떤 모델에 새로운 데이터를 입력으로 주어서 좋은 결과를 얻고 싶은 것이기 때문에 test시에 성능, 즉 train error와 test error의 격차를 줄이고 싶은 것이다.
격차를 줄이는 제일 쉽고 빠른 길은 Model Ensembles이다. 머신러닝에서도 종종 사용하는데, 모델을 하나만 학습시키는 것이 아니라 여러 개의 모델을 독립적으로 학습하여서 평균을 이용하는 것이다. 모델의 수가 늘어날수록 overfitting도 줄어들고 성능이 조금씩 향상된다. 2% 정도..하하 하지만 일관적으로 2% 정도 상승하기 때문에 어느정도 정확도를 끌어올린 모델에 적용한다면 유의미한 방식이다.
독립적으로 학습시키는 방법 외에도 하나의 모델에서 학습 도중 snapshot을 남겨서 앙상블할수도 있다. Test time에는 여러 snapshot에서 나온 예측값들의 평균을 사용하는 것이다. 모델을 한번만 학습시켜도 되기 때문에 앞선 방식보단 비용이 저렴하다.
또 다른 방법으로는 학습하는 동안 파라미터의 exponentially decaying average를 계속 계산하는 Polyak averaging이 있다.
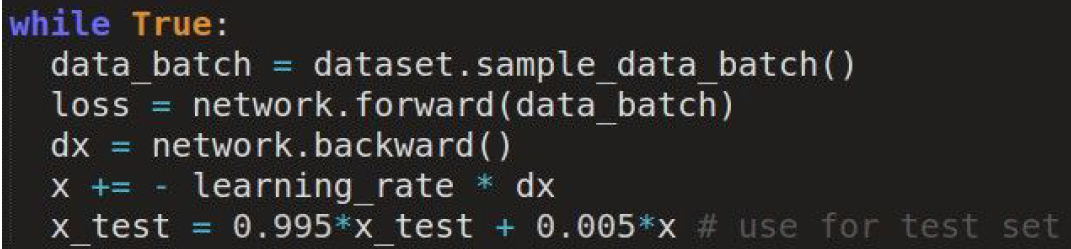
체크포인트마다의 파라미터를 그대로 사용하지 않고 어느정도 decay해서 사용하는 것이다.
3. Regularization
일반적으로 모델 앙상블은 test time에 여러 개의 모델을 돌리기 때문에 비용이 비싸다. 그렇기 때문에 단일 모델의 성능을 올리는 것이 중요한데, 이는 Regularization을 통해 해결할 수 있다.
이전 강의에서 이미 몇 가지 regularization 기법에 대해 살펴보았다.
Dropout
하지만 신경망에서 주로 사용하는 Regularization은 dropout이다. 이에 대해 살펴보자. 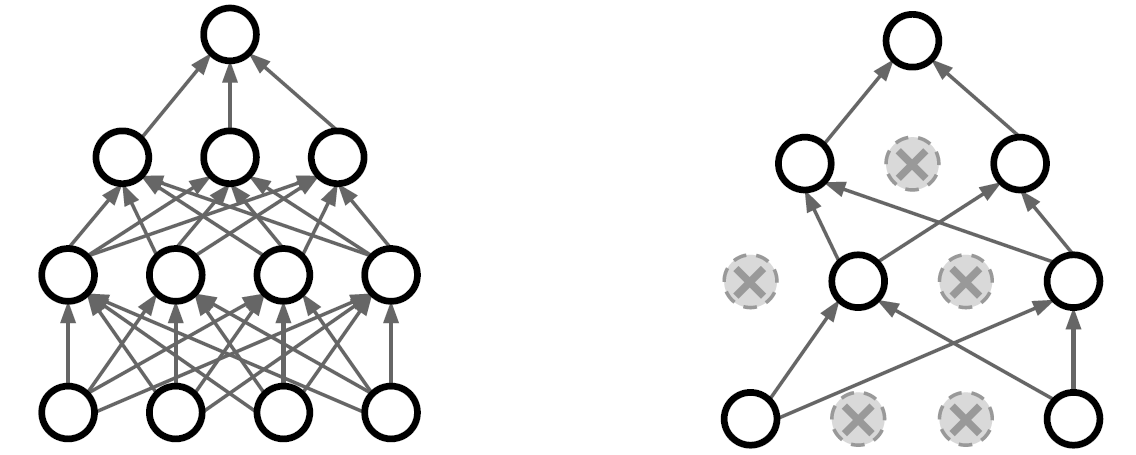
Dropout은 말 그대로 뉴런 간의 connection을 끊는 것이다. forward pass에서 임의의 뉴런을 0으로 만들어 학습에 참여하지 못하게 만드는 것이다. 또, foward pass할 때마다 0이 되는 뉴런이 바뀐다. 이러한 Dropout은 한 layer씩 진행된다.
Q1. Dropout은 일부의 activation을 0으로 만들어서 network를 훼손시키는데 왜 좋을까?
특징들 간의 상호작용을 방지한다. 즉, 신경망이 어떤 일부 특징에만 의존하지 못하게 해서 overfitting을 방지한다.
참으로 놀랍다!!!
또한 이런 dropout을 매번 다르게 적용하기 때문에 여러 가지 경우의 서브네트워크를 만들어낸다. 따라서 dropout은 거대한 앙상블 모델을 동시에 학습시키는 것과 같다고 볼 수 있다. 그러나 뉴런의 수가 많으면 많을수록 서브네트워크의 수가 기하급수적으로 증가하기 때문에 모든 서브네트워크를 사용할 수 없게 된다.
Q2. Test time에 dropout을 적용하면?
Dropout이 부여하는 임의성 때문에 적절하지 않다. 분류를 지멋대로 할 수 있고, 그 임의성을 평균 낼 수도 없다. 적분을 이용해서 근사화하더라도 임의성이 사라지진 않는다.
Q3. Test time에 dropout을 적용하는 방법은?
test time에 모든 뉴런에 dropout probability를 곱해준다.
dropout을 역으로 계산하는 방법도 있는데, test time에 dropout probability를 곱해주는 연산이 띠꺼워서 만든 방식이다. 그만큼 test time에 계산 효율을 중요시 여기기 때문이다.
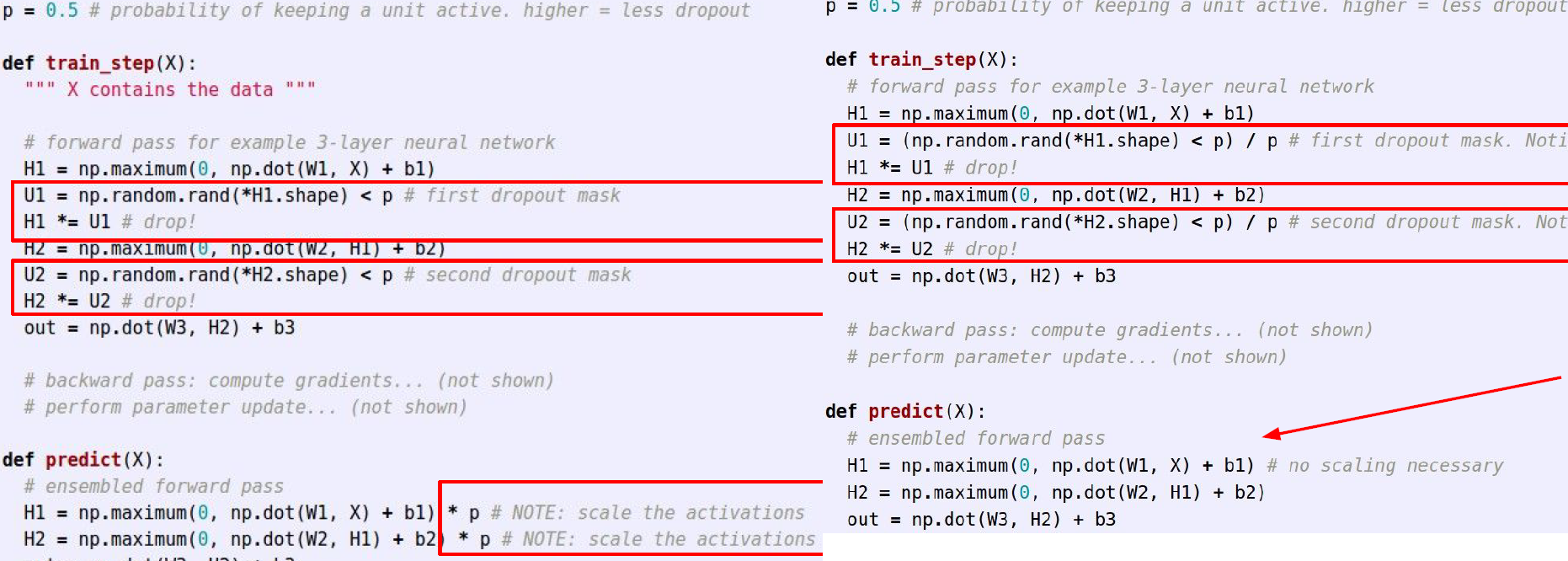
학습할 때 p로 나누어주어서 test 시에 p를 곱해줄 필요가 없게 만든다.
cf) dropout probability p에 대해서 약간 헷갈릴 여지가 있게 강의에서 서술하고 있는데, 코드를 기준으로 보면 결국 살아남은 노드들의 확률을 말한다.
또 dropout은 0으로 만들지 않은 노드에서만 Backprop.이 발생하고 수렴하면 결과값이 좋지만 수렴하기까지가 오래걸려서 전체 학습시간이 길다는 단점이 있다. iteration마다 업데이트되는 파라미터의 수가 dropout probability만큼 줄어들기 때문이다.

자!! 배운 것을 토대로 Regularization에 대해 정리해보자. 일반적으로 train time에 네트워크에 randomness를 추가해서 training data가 overfit하지 않게 만든 다음, test time에서는 randomness를 평균내서 근사(일반화)한다.
이와 비슷한 동작을 하는 것이 우리가 앞서 배운 Batch Normalization이다. BN도 마찬가지로 train time에 mini batch를 두어 랜덤하게 추출하고 normalize하는 식으로 stochasticity가 있다. Test time에선 minibatch가 아닌 global하게 수행해서 stochasticity를 평균낸다.
실제로 BN에서 Dropout을 사용하지 않는데, 충분한 regularization효과가 있기 때문이다. 하지만 BN과 달리 dropout은 맘대로 조절 가능한 probability 변수 p가 있어서 아주 유용하다.
Data Augmentation
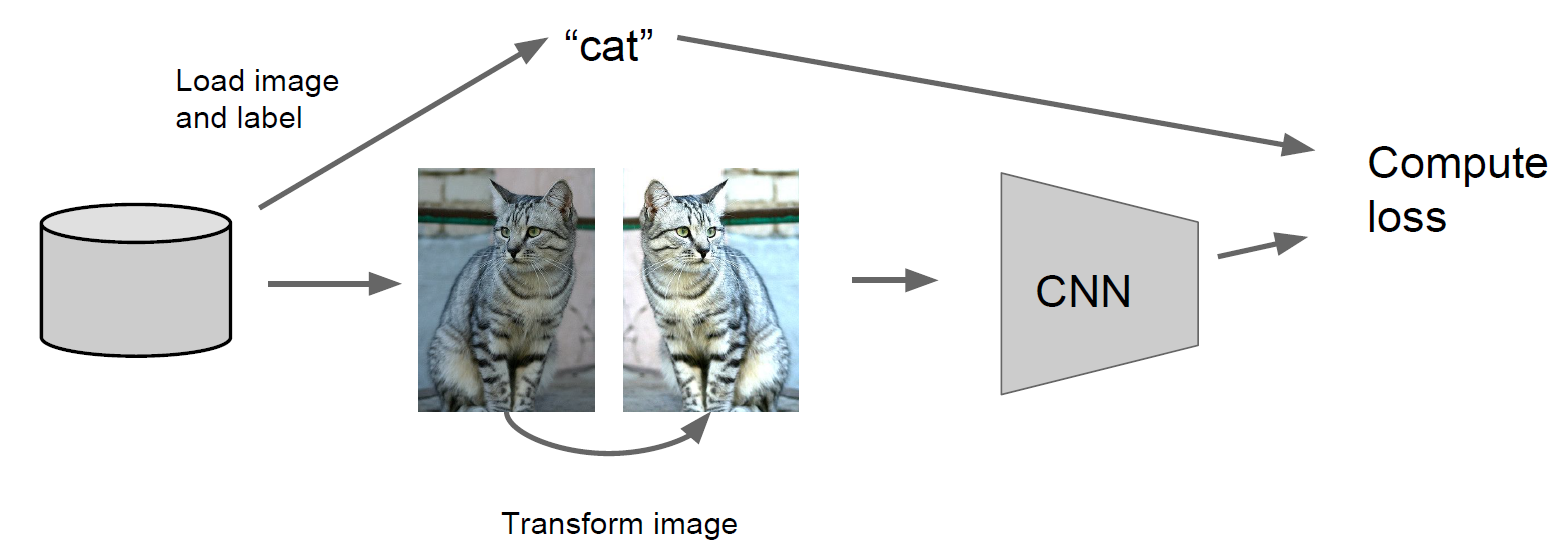
또 다른 Regularization 방법이 있는데, 바로 data Augmentation이다. 어찌보면 제일 직관적으로 떠올릴 수 있는 방법인데, 데이터를 무작위로 변환시키는 것이다. 가령, input이 이미지라면 이미지를 여러 방식으로 뒤집는 식으로 말이다. 아래 그림은 CNN 모델에서의 data Augmentation의 예시이다.
커여운 냐옹이쉑..
이 외에도, 학습할 때 이미지를 임의의 다양한 사이즈로 자르거나 확대해서 사용할 수 있다. Test time에서는 마찬가지로 이를 평균낸다. ex) 4 corners + center, flips
또한 color jittering이라고 PCA의 방향을 고려해서 color offset을 조절하는 것이다.
이처럼 label을 바꾸지 않으면서 하나의 이미지를 여러 이미지로 변환할 수 있다. 아래의 방법들이 가능하다.
- Translation
- Rotation
- Stretching
- Shearing
- Lens distortions 등등
결국 Train time에 입력 데이터에 임의의 변환을 주면서 일종의 regularization 효과를 얻게 된다. 그 이유는 test time에 결국 그것들이 average out / marginalize out(확률적 의미일 때)되기 때문이다.
우리가 배운 Dropout, BN, Data Augmentation 외에도 1) DropConnect, 2) Fractional Max Pooling, 3) Stochastic Depth이 있다.
1) DropConnect는 Dropout과 달리 activation이 아닌 weight matrix를 임의적으로 0으로 만들어준다.
2) Fractional Max Pooling은 pooling 연산을 수행할 지역을 임의로 선정하여 test time에 average out하는 것이다. 이때, pooling하는 지역을 고정하거나 여러 개의 지역을 만들어 average out한다.
3) Stochastic Depth는 train time에 네트워크의 layer를 임의로 drop해서 일부만 사용한다. 그러나 Test time에는 전체 네트워크를 다 사용한다.
Q1. 보통 하나 이상의 regularization 방법을 사용하는가?
일반적으론 BN을 많이 사용한다. 보통 잘 동작하기 때문인데, overfitting이 발생한다 싶으면 다른 방법을 추가해볼 수 있다.
4. Transfer Learning
지금까지는 train error와 test error의 격차를 줄이는 것을 도와주는 Regularization에 대해 살펴보았다.
결국 train set에 overfitting되지 않게 하는 것이 주 목표인데 언제 overfitting이 일어날까?
제일 먼저 생각해볼 수 있는 일반적인 경우는 학습시킬 수 있는 충분한 데이터가 없을 경우이다. 이러한 문제를 해결하는 것이 Transfer learning이다.
Transfer learning은 기존에 학습된 모델에서 마지막 레이어만 새로 초기화시키고 학습한다. 만약 갖고 있는 데이터셋이 아주 크다면 더 많은 레이어를 학습, 업데이트, 초기화(fine tuning)시키고 학습시킨다.

위 그림은 CNN에서의 transfer learning인데, 가령 ImageNet의 데이터로 학습된 모델에 우리가 분류하고자 하는 것을 마지막 FC layer에 초기화시켜서 사용할 수 있다. 즉, 모델이 계산한 최종 level의 feature와 결과값인 class score만 연결해주는 것이다.
하지만 기존의 learning rate 보다는 작은 값을 사용해야 한다. 그럴게 아니라면 transfer learning을 하는 의의를 훼손하는데 기존의 가중치들이 이미 잘 학습되어 있는 모델을 사용하고자 하는건데 그걸 무시한다는 것은 앞뒤가 안맞는다.
데이터셋의 유사성과 데이터 수에 따라 어떻게 trasfer learning을 해야할지는 아래와 같다. 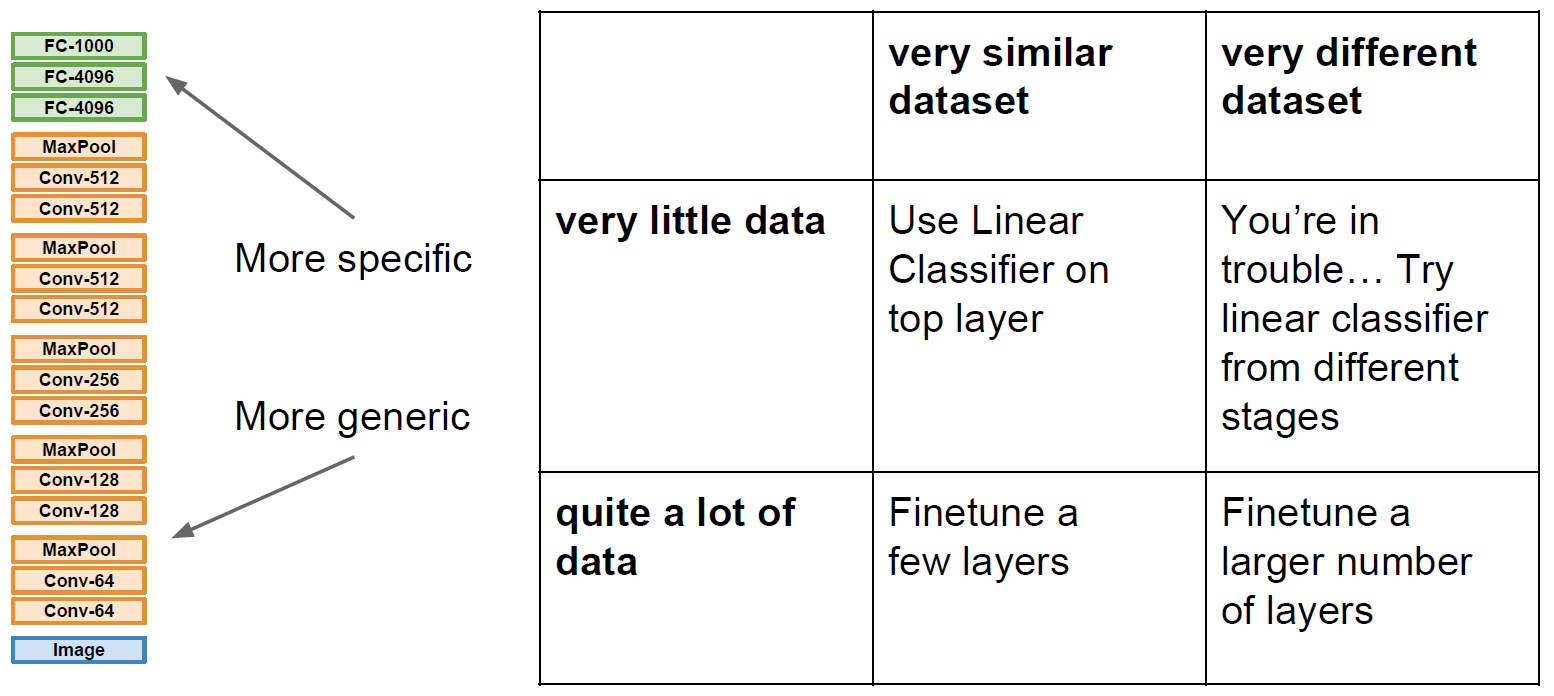
- 데이터 수가 적고 유사한 데이터일 경우
그저 top layer에 선형 분류기를 사용하면 된다. Transfer learning을 사용하기에 매우 바람직한 상황이다. - 데이터 수가 많고 유사한 데이터일 경우
일부 layer를 Fine tuning해본다. - 데이터 수가 적지만 매우 다른 데이터일 경우 쉽지 않다..Transfer learning이 잘 안 먹힌다
- 데이터 수가 많고 매우 다른 데이터일 경우 3번보단 나은 상황이다. 다수의 layer를 fine tuning해본다.
Transfer learning with CNN
CNN 모델에서 Transfer learning은 매우 많이 사용된다. ex) Object detection(Fast R-CNN), image captioning(CNN+RNN)
만약 어떤 문제가 있고, 이 문제에 대해 dataset이 크지 않은 경우라면 task와 유사한 데이터셋으로 학습된 pretained model을 다운로드 받아서 일부를 초기화하고 fine tuning한다.

{kind=link}